
Main Menu
Welcome





One particular aspect that has been bugging me for years is the ridiculously tedious way in which we have to deal with the scientific literature. We browse through tables of contents, save database-keyword searches in various places, subscribe to press releases or other alerts in again various other places and listen to podcasts. This not only leads to unnecessary redundancy, it also means I see a lot of scientific publications which have nothing to do with my research at all. In fact, the overwhelming majority of paper titles I read are of no interest to me whatsoever. In short: I spend somewhere around 10h every week sifting through irrelevant stuff only to find one or the other nugget in there every other week or so. This discovery per search time ratio is just anoyingly low.
Here's another example how innovation in the general sphere solves an analogous problem, while scientists still don't have anything comparable at their disposal: paper.li. They parse all the URLs in the Twitter feeds you subscribe to and (using 'paper.li magic') generate a 'newspaper' with the most prominent stories of the past 24h. Here's what mine looked like today:
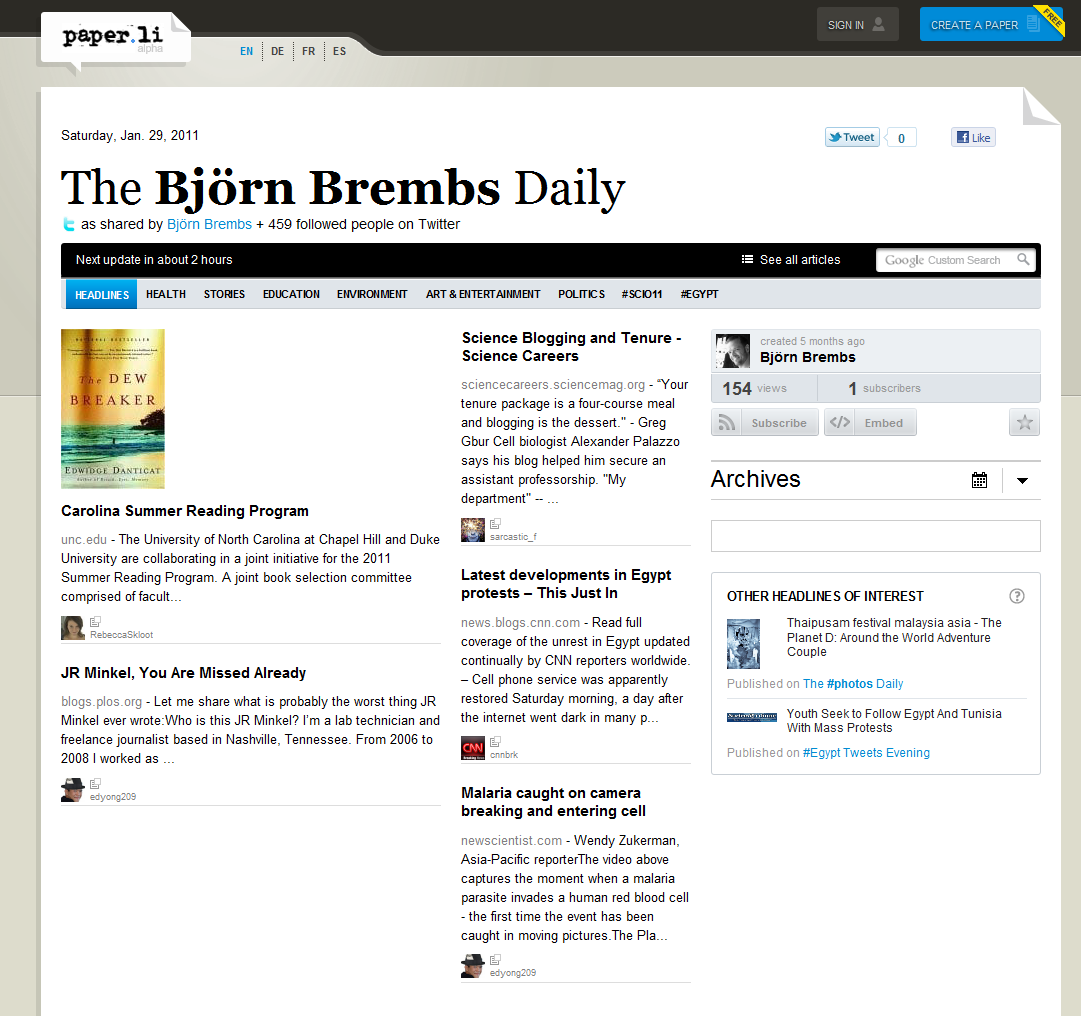
This works so well that by now I'm selecting who I'm following on Twitter partially by what kind of links they post. I rarely ever read Twitter posts or post there myself - but I do at least scan my paper.li every morning.
When will scientists be able to get a newspaper like this on their desktop every morning? I'd like to be able to configure it such that the largest headlines on top are the titles (or running heads) of the most important keywords I use for my research. Next to these headlines should be the publications which cite my own work: they must be relevant, too. Somehwere towards the top should be the papers from people I know work on topics I also work on, e.g. collaborators or competitors. Anything they publish will be very relevant for my own work. Below those should be the papers that my wider circle of colleagues has either bookmarked or commented/blogged on - a number and order I can specify. My colleagues work in related fields so much of what they discover will be important for me as well. Towards the end should be general reviews on topics I'm interested in, but not expert enough to actually read the papers. This is also the section where relevant press releases may be listed. The text snippets can come from the abstracts or from author provided summaries. Images can be pulled from the publication figures or be provided by the authors for exactly this purpose.
In principle, this sort of service could exist today, paper.li shows that the technology is already available. One of the problems hindeing an actual implementation is that scientific publications are scattered across about 24,000 different venues and there isn't a single RSS feed of scientific literature one could easily parse through. Another problem is that there isn't a sufficiently well-developed. standardized rating, commenting or bookmarking system developed to generate some sort of ranking algorithm. The whole new information technology in the scientific sphere is either nonexistent, or so fractionated that it never reaches the critical number of participants above which it would become truly helpful and worthwhile. This technology requires large numbers and the scientific community will only reach those when the approaches are sufficiently large-scale.
Perhaps the RSS feed of the largest journal in the world may be suitable for such a project? PLoS One publishes thousands of articles per year, some of which get bookmarked, rated or commented on and in principle their database would allow services such as a paper.li to extract the sort of scheme I've described above. The more large venues such as PLoS One grow, the more significant the leverage of new information technology will be.
Clearly, initiatives such as ORCID, which aims to give every researcher a unique identification number will help building such services by pre-configuring templates and helping to standardize any form of access to the ultitude of literature silos. Mass migration of authors away from niche journals and towards large publication venues such as PLoS One will also help facilitate the development of technology assisting researchers in handling the flow of information. Cameron Neylon put his frustration over these issues in these words:
We don’t need more filters or better filters in scholarly communications – we don’t need to block publication at all. Ever. What we need are tools for curation and annotation and re-integration of what is published. And a framework that enables discovery of the right thing at the right time. And the data that will help us to build these. The more data, the more reseach published, the better.
Scientists need information technology to efficiently search, filter, rank and discover what their colleagues are publishing about. Paper.li provides a glimpse of what such a technology might one day look like, but so far, only the general public is allowed to use it, scientists are still stuck with stone-age technology. When will science catch up with modernity?Posted on Sunday 30 January 2011 - 15:37:29 comment: 0
{TAGS}
{TAGS}
You must be logged in to make comments on this site - please log in, or if you are not registered click here to signup
Render time: 0.0935 sec, 0.0074 of that for queries.