This post was originally published on the London School of Economics “Impact of Social Sciences” blog, on July 30, 2013:
In various fields of scholarship, scholars accrue reputation via the proxy of the containers they publish their articles in. In most if not all fields, scholarly journals are ranked in a hierarchy of prestige. This prestige is reflected in the rejection rates of the individual journals: the more prestigious a journal, the more authors desire publishing in it, the higher the rejection rate.
However, much like the potential patrons lining up in front of a new – but perhaps empty – club, or the peasants stealing potatoes from Parmentier’s fields at Sablon, only few scholars are asking if there are any other indicators of quality that correlate with journal rank, besides perceived or manufactured exclusivity. A recent overview of the work of these few scholars revealed that very few measures showed any correlation at all: neither was the methodology any more sound in higher ranking journals, nor do they fare better at replication tests. A few measures, such as crystallographic quality, effect size accuracy or sample size have been reported to correlate negatively with journal rank, while the literature does not contain a single measure related to quality that correlates positively with journal rank.
In the light of such data, it is perhaps not surprising, that one of the strongest correlations of journal rank is that with retractions: high-ranking journals publish research that is a lot less reliable than that in other journals: the combination of prestige attracting surprising and counterintuitive discoveries, combined with not only average (perhaps even sub-par) quality, but also increased readership and hence scrutiny is a recipe for disaster. The data in plain words: scientific top journals are like tabloids: widely read, but not necessarily trustworthy.
These data provide empirical evidence to support the hypothesis that the incentive structure in science can be blamed for much of the alarming trends of the past decades, such as the exponentially increasing retraction rates, ever larger and more frequent cases of fraud and the replicability crisis. Apparently, the current system of journal prestige favors scientists who are effective at marketing their research to prestigious journals, but not those whose research is reliable. In addition, the prestige bestowed by journal rank is what prevents authors from seeking alternative publishing venues (or they would risk their careers), contributing to the serials crisis of legacy publishers charging exorbitantly for subscriptions.
Figure 1: Current Trends in the Reliability of Science
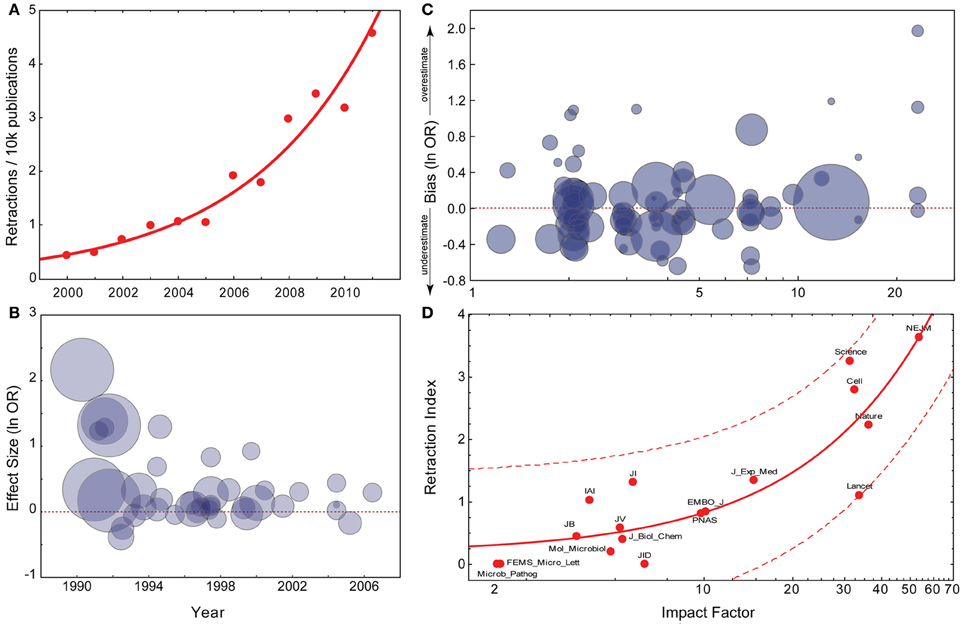
(A) Exponential fit for PubMed retraction notices (data from pmretract.heroku.com). (B) Relationship between year of publication and individual study effect size. Data are taken from Munafò et al. (2007), and represent candidate gene studies of the association between DRD2 genotype and alcoholism. The effect size (y-axis) represents the individual study effect size (odds ratio; OR), on a log-scale. This is plotted against the year of publication of the study (x-axis). The size of the circle is proportional to the IF of the journal the individual study was published in. Effect size is significantly negatively correlated with year of publication. (C) Relationship between IF and extent to which an individual study overestimates the likely true effect. Data are taken from Munafò et al. (2009), and represent candidate gene studies of a number of gene-phenotype associations of psychiatric phenotypes. The bias score (y-axis) represents the effect size of the individual study divided by the pooled effect size estimated indicated by meta-analysis, on a log-scale. Therefore, a value greater than zero indicates that the study provided an over-estimate of the likely true effect size. This is plotted against the IF of the journal the study was published in (x-axis), on a log-scale. The size of the circle is proportional to the sample size of the individual study. Bias score is significantly positively correlated with IF, sample size significantly negatively. (D) Linear regression with confidence intervals between IF and Fang and Casadevall’s Retraction Index (data provided by Fang and Casadevall, 2011).
Thus, the picture emerges that by reforming the scholarly publishing structure, we can solve several current issues at once:
- We can reward reproducible discoveries, rather than publications, increasing scientific reliability.
- We can save lives and boost the world’s economies by providing universal open access to all of the scholarly literature
- We can save billions every year in subscription costs
What do we need to do to accomplish this? One solution is to use the already existing infrastructure and know-how in our scholarly institutions: collectively, our libraries and computing centers have all it takes to serve the world not only the two million new publications every year, but also all the literature from the past. There is no reason why publishers should be required for this task any more – libraries around the world are already publishing the works of their faculty. The SciELO (Scientific Electronic Library Online), originally from Brazil, but now used in most Latin American countries and South Africa, is a cooperative electronic publishing system which now publishes over 900 open access journals at a cost of just US$90 per article. Compare these US$90 to the US$4000 per article we currently pay on average for legacy publishing or with the US$30,000-40,000 for articles in the most prestigious journals. As mentioned above, the evidence suggests that this gigantic surplus is not buying any added value. With a total yearly revenue of legacy publishing around US$10 billion, the scholars are wasting approximately US$9.8 billion every year, compared to an institution-based publishing system like SciELO, and even more if we would use preprint systems such as Arxiv.
The success of SciELO demonstrates that such an alternative is technically feasible, scalable, significantly cheaper than our current model, and would provide universal open access to the whole planet if the rest of the world would adopt it. Thus, universal adoption of SciELO alone would cover points 2 and 3. Obviously, this is not only one of several solutions, but also an example of how easy it is technically to effectively reform scholarly publishing.
The remaining first point can be addressed by identifying alternative metrics to accrue reputation. Once we have full access to all the literature, we can use the scientific method not only for the identification of such metrics, but we can also use this method to test how to ideally design a reputation system that aligns the incentives for each individual researcher with science and the public. Once we have taken back the control over the fruits of our labor: literature, data and software, we can reward scientists who excel at designing software that evaluates data, who are unsurpassed at collecting and curating large amounts of data, who shine with their talent for experimental design and consequently generate reproducible research, but who are not necessarily the best salesmen. We can reward the crucial personnel without which the scientific enterprise could not exist, but who currently fall through the cracks.
These ideas demonstrate that by overcoming journal rank and replacing it with a scientific reputation system as part of an institution-based publishing service for scholarly literature, software and data, we could collectively free more than US$9b every year for science and innovation. By further delaying publishing reform, we not only keep wasting tax-payer money, we also continue to reward salesmen who may possibly also be great scientists (if we are lucky) and to punish excellent scientists who are not extraordinary marketers. It does not take an evolutionary biologist to predict what this sort of selection will do to the scientific community within only a few generations.













