“an academic career, in which a person is forced to produce scientific writings in great amounts, creates a danger of intellectual superficiality”
Albert Einstein
Ever since Reagan and Thatcher made neoliberal ideas palatable to an unsuspecting public, concepts such as “New Public Management” or the more general notion that competition between institutions and individuals are key to eliminating the (probably nonexistent or at least negligible) problem of “dead wood”, have slowly crept into academia as well.
The consequences on the institutional level are quite well documented: The increase of the precariat of (adjunct) faculty without benefits or tenure, a growing layer of administration and bureaucracy, or the increase in student debt. In part, this well-known corporate strategy serves to increase labor servility. The student debt problem is particularly obvious in countries with tuition fees, especially in the US where a convincing argument has been made that the tuition system is nearing its breaking point. The decrease in tenured positions is also quite well documented (see e.g., an old post).
On the individual level, tenure, promotion and funding in many places now depend on the number of publications (in certain journals; i.e., “publish or perish”) or one’s creativity in designing the most expensive way to do their research (i.e., amount of grant income). While the incentives to waste tax-funds are rather obvious, it is probably more difficult to immediately see anything wrong with rewarding productivity. After all, researchers live off the public teat, shouldn’t they provide something tangible in return?
The issue lies, of course, in how to measure productivity. In many areas, not only science, Einstein’s dictum holds: “not everything that can be counted counts and not everything that counts can be counted”. There are at least two main issues with exerting selection pressure on scientists by using a count of research papers.
- It is likely only of specific value to some positions/institutions to hire/promote/fund researchers who excel at milking the most publications out of a given research question. In other words, while we should not exclude this kind of research, it is probably not to a general benefit if we primarily select those scientists who are especially gifted for identifying the fields of inquiry where a research paper is always just a fortnight away. Applied across the board, this strategy leaves the more challenging research questions without adequate staffing.
- In the experimental sciences, there is a statistical risk that the most productive researcher is also the one producing the least reliable publications. The point was made in great detail by Daniel Lakens in his paper “Sailing From the Seas of Chaos Into the Corridor of Stability: Practical Recommendations to Increase the Informational Value of Studies”. In brief, the argument is that a research strategy that aims at many low-powered studies (rather than fewer adequately powered ones) yields more statistically significant (and hence publishable) results. The figure (Fig. 1 in Daniel’s paper) below exemplifies this very nicely, I think:
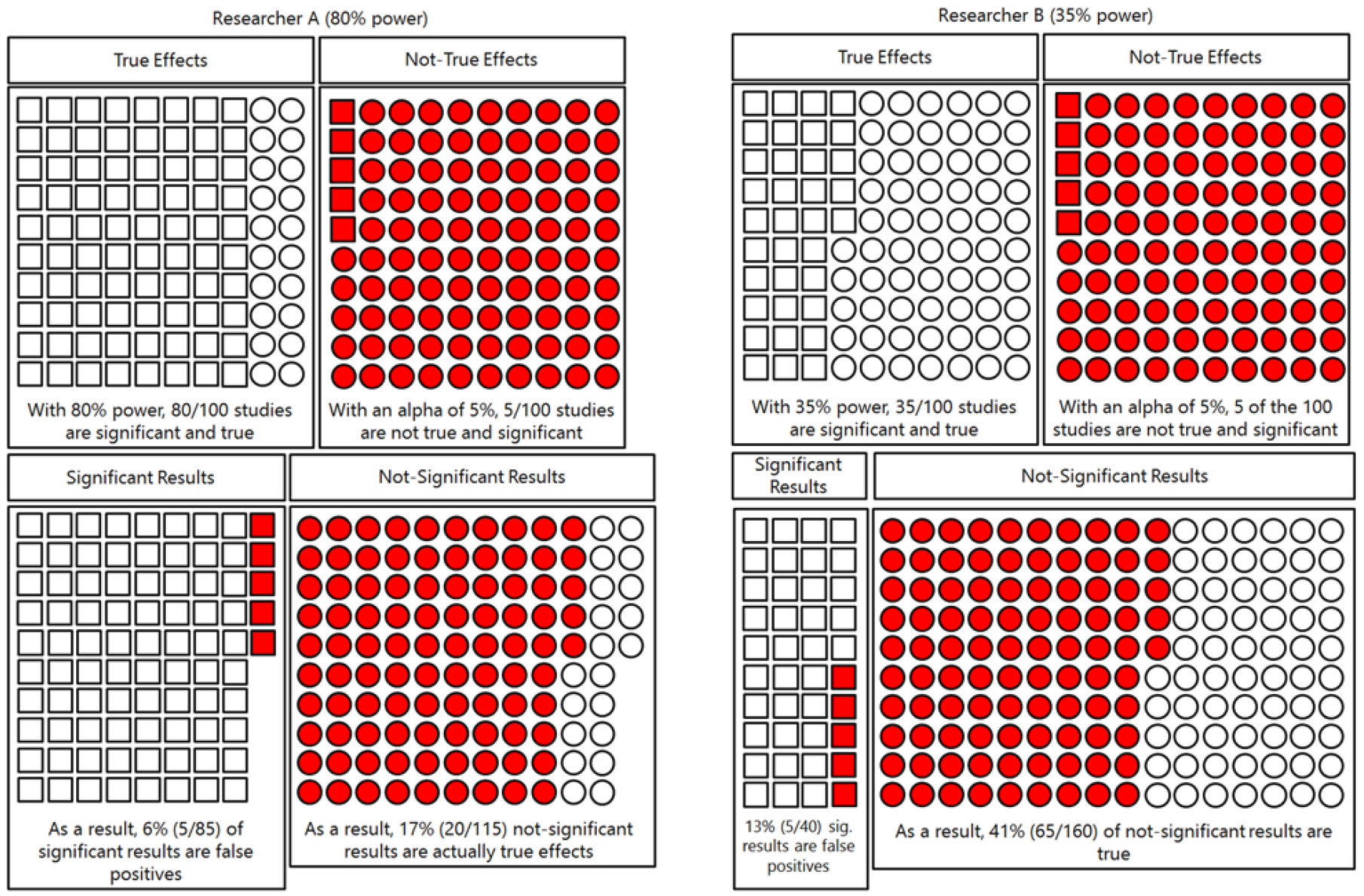
Ratio of false-to-true positives and false-to-true negatives for the two researchers performing studies at 80% or 35% power. Both Researcher 1 and Researcher 2 conduct 200 experiments in which they examine 100 true ideas (in white) and 100 false ideas (in gray). Squares represent significant results, and circles represent nonsignificant results
In the above example, if one were to assume that researcher B would be able to do, say, 100 studies, researcher A would be able to accomplish 44 studies in the same time, all else being equal. In this hypothetical scenario, Researcher B would end up with 21 significant results, while Researcher A would only obtain 19.
We obviously don’t really know many of the parameters required to accurately estimate how successful any such strategies would be in our current research settings. [UPDATE: A modeling study (adequately titled “the natural selection of bad science“) recently confirmed that the above scenario is indeed quite realistic.] However, the fact that one can conceive of plausible situations where productivity is an indicator of sloppiness ought to ring alarm bells, especially in times when the reliability of science is becoming a major concern.
Hence, for these two reasons alone, be wary of the competence of anyone who uses ‘productivity’ as a criterion to evaluate researchers.
Together with the fact that we also reward scientists who publish in journals with a track record of unreliability, we should not discard concerns off-hand that we ourselves have contributed to the current situation by falling prey to the neoliberal idea that measurable performance is the prime criterion by which we can justify our selection of faculty. If the available data are correct indicating that we may have been selecting those researchers who publish the least reliable science for several decades now, we ought not to be surprised if we find that the reliability of science has been slipping.
P.S.: A similar argument has been made today in an editorial (easier to read with less data and statistics). See also this relevant post from 2013.
P.P.S.: On Facebook, Aaron Blaisdell from UCLA commented that counting papers is “a great way to measure whether a scientist puts ambition ahead of curiosity, scientific rigor and the quest for knowledge and understanding.” In this discussion, Bill Hooker was quick to point out that it may also measure how caught up in the system early career researchers have become.
Of course, the basic idea behind this argument isn’t all that new:
















Number of papers alone is not a measure of research efficiency, as stated. But what is? The best metric I arrived is the total grant divided by the amount of results (approximately equal to number of papers if salami method has not been employed). This should give a good estimate on the budget efficiency of a particular researcher. Of course to be compared only within the same specific field.
While I really like the “dollar per paper” approach in principle, similar criticisms of course apply: you select for those who can milk a research field and/or identify low-hanging fruit. Not bad, but likely not a good approach if applied generally.
As I see it, there are no good general indicators (and if they are, they’ll likely succumb to Goodhart’s law anyway: https://en.wikipedia.org/wiki/Goodhart's_law )
What is required is a very large collection of different metrics that serve three main purposes:
1. Allow each evaluation to select for the traits that matter for them
2. Make it difficult for individuals to capitalize only on a small section of scholarship
3. Make it difficult to game the system as the task becomes more complicated with every added metric.
An added benefit of such a large set is that each individual metric becomes devalued by inflation.
In effect actually read the papers and then have an in-depth discussion at interview
Of course read the papers is the best solution, but here in Brazil thousands of scientist apply for a yearly productivity grants, in the end they can read all projects and papers, and rely of misleading metrics.
To have more metrics describe a particular scientist, each metric highlighting their own traits, just increases entropy! Not good. There needs to be a way of comparing within the particularity of a specific field, a triage, so that with a handful, you can then proceed to read the papers.