The question in the title is serious: of the ~US$10 billion we collectively pay publishers annually world-wide to hide publicly funded research behind paywalls, we already know that only between 200-800 million go towards actual costs. The rest goes towards profits (~3-4 billion) and paywalls/other inefficiencies (~5 billion). What do we get for overpaying such services by about 98%? We get a literature that essentially lacks every basic functionality we’ve come to expect from any digital object:
- Limited access
- Link-rot
- No scientific impact analysis
- Lousy peer-review
- No global search
- No functional hyperlinks
- Useless data visualization
- No submission standards
- (Almost) no statistics
- No content-mining
- No effective way to sort, filter and discover
- No semantic enrichment
- No networking feature
- etc.
Moreover, inasmuch as we use the literature (i.e., in terms of productivity and/or journal rank) to help us select the scientists for promotion and funding, we select the candidates publishing the least reliable science.
Taken together, we pay 10 billion for something we could have for 200 million in order to buy us a completely antiquated, dysfunctional literature that tricks us into selecting the wrong people. If that isn’t enough to hit the emergency brakes, what is?
We may not be able to buy paradise with 10b annually, but with such a low bar, it’s easy to get anything that’s at least not equally abysmal. The kind of modern technology we can buy would probably solve most of the most pressing issues with our literature, cover all our needs in terms of data and make sure we can cite and reuse all scientific code in a version-controlled manner – and then leave a few billion to play around with every year.
With the fruits of our labor firmly in our own control, we would have a flourishing market of services, such that whenever our digital infrastructure would lack the functionalities we expect or becomes too expensive, we can either switch service providers or hire our own experts without loosing our content.
As an added benefit, cutting the steady stream of obscene amounts of money to a parasitic industry with orthogonal interests to scholarship would prevent further buyouts of scholarly ventures such as Mendeley or SSRN and with it the disappearance of valuable scholarly data in the dark underbelly of international corporations.
One reason often brought up against canceling subscriptions is that faculty would complain about the lack of access subscription cancellations would entail. However, already published literature can in principle (although substantial technical hurdles still need to be overcome) be accessed via a clever combination of services such as automated, single-click inter-library loan, LOCKSS and Portico. Moreover, some libraries have seen substantial cost-savings by canceling subscriptions and instead supporting individual article downloads. Finally, institutional repositories as well as pre-print archives need to be leveraged whenever the publisher-version isn’t available. After all, we have DOAI and the pre-print versions are almost identical to the final article. With such an effort, most users likely wouldn’t experience more than maybe a few hiccups, but they’re already used to patchy access anyway, so it wouldn’t look vastly different from what people are experiencing now. In fact, if subscriptions were canceled, there would be a substantial incentive to get the most modern access tools and to keep them up to date, so for many institutions this might actually increase the spread and ease of access, compared to the current largely subscription-only access model. Thus, it is technically feasible to cancel all subscriptions in a way that most users probably wouldn’t even notice it. Essentially, all we’d have to manage is replacing one patchy access system with another patchy access system. While this may not exist out-of-the-box, yet, it should not be too complicated to assemble from existing technologies. One could call this a “legal Sci-Hub“. Add to that an information campaign that alerts users that while no major disruption is anticipated during the transition, some minor problems may arise, and everyone will support this two decades overdue modernization.
Another reason often provided is that the international cooperation between institutions required for such a system-wide cancellation to be effective were impossible to accomplish. That is a problem less easily dismissed than the supposed lack of access to the literature. After all, some governments explicitly don’t want their institutions to cooperate, they want them to compete, and even to develop “world-class competitiveness” (page 17):

In this regard, I recently listened to a podcast interview with Benjamin Peters, author of “How not to network a nation“. His description of the failure to develop the internet in the Soviet Union (compared to the successful developments in the West) reads like an account of how not to make open access a reality:
the American ARPANET took shape thanks to well-managed state subsidies and collaborative research environments and the Soviet network projects stumbled because of unregulated competition among self-interested institutions, bureaucrats, and others.
We need the same collaborative spirit if institutions are to abandon subscriptions, just as they cooperated to spend money to draw cables between institutions, even though they were separated by borders and even oceans. If in the 1980s, our institutions collaborated across nations and continents to spend money on a research infrastructure nobody yet knew, can’t they collaborate now to save money being wasted on an obviously outdated infrastructure? Has neoliberal worship of competition poisoned our academic institutions to such a degree, that within 25 years they went from cooperating even if it means spending money to never cooperating even if it means saving money? I refuse to believe that, even though that’s what some try to tell me.
Instead of trying to tell scholars to behave ethically in spite of the downsides to them personally, maybe we ought to tell institutions that our infrastructure is outdated and that we need the functionalities everybody else but academics are enjoying? We need to get the same mechanisms going that in the 1980s got our universities to invest in networking hardware and cables, despite a functioning telephone and snail mail system. Cancelling subscriptions doesn’t mean losing access, so nobody can tell me that canceling subscriptions is more difficult than installing compatible networking hardware across the globe. I’m now paying for my phone bills out of my budget, while my skype calls are provided by my university. Maybe rather than trying to convince scholars to choose the ethical over the advantageous, it would be more effective to ask our institutions to provide us with modern technology and have those who still want to use the legacy version pay for it themselves?
Framing our issue as an ethical one (“the public needs access to publicly funded research!”) may work, but it is a slow, ineffective and uncertain approach. Framing it as merely a technical modernization strikes me as potentially quicker, straightforward and effective.
UPDATE (May 23, 2016):
Some people have asked for evidence that canceling subscriptions and instead relying on individual downloads can save money. Besides hearsay from several libraries, this is a piece of evidence which should be quite convincing that this can work for some publisher/library combinations (click for larger version):
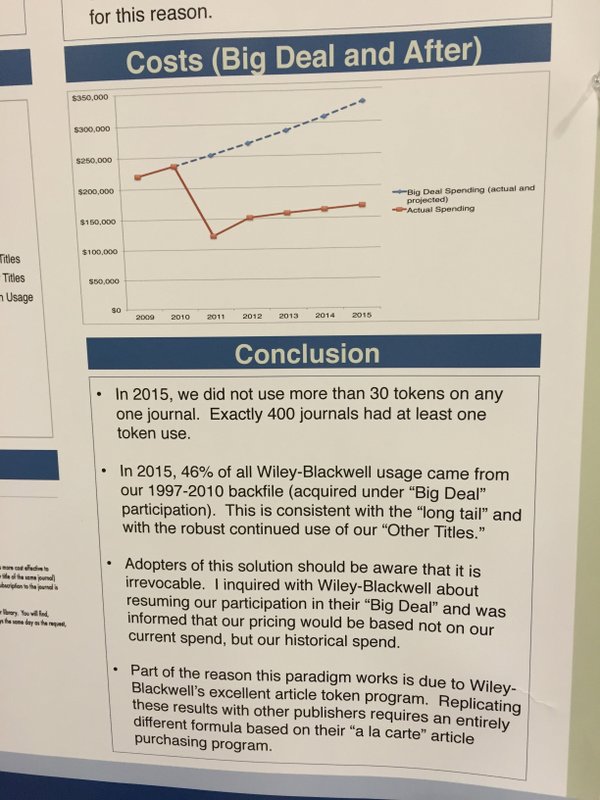 So if libraries were to cooperate in identifying more such opportunities and then cleverly combine this action with LOCKSS and/or Portico as well as smart (single-click) ILL between those libraries whose Big Deals have already run out and those which are still running, given enough participants, almost all of the already published literature ought to be accessible. It may not be trivial, but it’s definitely feasible and the technical problems are not the main obstacle – it’s the collaboration that needs to be established. Moreover, this only needs to work for a relatively short time, until most of the journals have run dry of funding and ceased to exist.
So if libraries were to cooperate in identifying more such opportunities and then cleverly combine this action with LOCKSS and/or Portico as well as smart (single-click) ILL between those libraries whose Big Deals have already run out and those which are still running, given enough participants, almost all of the already published literature ought to be accessible. It may not be trivial, but it’s definitely feasible and the technical problems are not the main obstacle – it’s the collaboration that needs to be established. Moreover, this only needs to work for a relatively short time, until most of the journals have run dry of funding and ceased to exist.
Update to the update (June 8, 2016): Similar to the example above, other libraries have canceled big deals and come out ahead. Also here, providing previously subscribed content combined with rapid ILL from collaborating institutions worked just fine. (Link thanks to Micah, in the comments)
Indeed, the OA Tracking project at Harvard is collecting such examples under their own oa.cancellations tag. Quite a nice list of cancellations there. It’s a fact, canceling subscriptions can be done without faculty revolt and with substantial savings.
UPDATE II
Triggered by online discussions, a few hypothetical use cases:
- A user is requesting an older document from a journal that their institution longer subscribes to, but was accessible in the past. The link resolver checks if it can be served via LOCKSS or Portico. If not (weird that LOCKSS/Portico would not serve if content was already purchased before!?), then the resolver extracts the article meta-data (importantly, the DOI for use with DOAI) and screens the institutional repositories or places such as PubMedCentral, arXiv/bioarxiv or ResearchGate for the document. If all that fails, the link resolver checks for ILL availability with an institution whose Big Deal has not expired, yet. If none of these 3/4 services can serve the document, then ask user if they want to send copy request to author (single click) or download individual article and pay the fee (faculty get informed about their usage/costs!).
- A user is requesting a brand new article from a journal that their institution is not subscribing to. The link resolver extracts the article meta-data (importantly, the DOI for use with DOAI) and checks for availability in repositories. If unavailable, check for ILL. Both not available, ask user if they want to send copy request to author (single click) or download individual article and pay the fee (faculty get informed about their usage/costs!).
- A user is requesting an older document from a journal their institution never subscribed to. The link resolver extracts the article meta-data (importantly, the DOI for use with DOAI) and checks all relevant repositories, then ILL. If both fail ask user if they want to send copy request to author (single click) or download individual article and pay the fee (faculty get informed about their usage/costs!).
UPDATE III (Jan 17, 2017):
I’ve collected a short list of ten different ways to access journal articles without a subscription, nine of them completely legal. Clearly, canceling subscriptions (or not renewing them) is not the big deal it once was. If we used the saved funds to invest it in our digital infrastructure, by the time all subscriptions had run out, we would look back and wonder what took us so long.
UPDATE IV (Feb 16, 2017):
Since the start of 2017, about 60 German institutions lost all access to the journals of publisher giant Elsevier. According to a news report:
The loss of access to Elsevier content didn’t overly disturb academic routines, researchers say, because they found other ways to get papers they needed
It’s official. It works. We don’t need subscriptions.
UPDATE V (May 2, 2017):
In addition to the long list of reports about successful and painless subscription cancellations, there is now an evaluation of an informal survey of 31 US-based libraries. 24 of the sample had cancelled Big Deal subscriptions and the author’s conclusion was that “relatively few libraries that actually do cancel their Big Deals end up regretting it”. Obviously, more and more libraries realize that subscriptions are bad value for money and do just fine without them.
UPDATE VI (December 14, 2017):
SPARC is now also tracking big deal cancellations across the globe. It can be done, the evidence is out there for all to see.












Hi,
thanks for this article. Just curious: when you say “Moreover, some libraries have seen substantial cost-savings by canceling subscriptions and instead supporting individual article downloads.” do you have any references for this point I could follow up on?
thanks, Stephen
I’ve updated the post with one piece of evidence. The rest I have is just hearsay from different places, unfortunately.
Apathy and a persistent belief in prestige being correlated with accuracy. Regarding the former and the payment of APCs be it open or otherwise, senior colleagues I know have stated to me that ‘they’ don’t pay as in personally, the money is already allocated and therefore they are not going to lose any sleep over the issue. I have mentioned that collectively this money is therefore lost from research and it’s a kind of a this it the way it’s done approach. Better to focus on your research or stick your head in the sand dependant on viewpoint.
You…you do realize that Interlibrary Loan works because libraries have subscriptions to it right? Some…well a lot of libraries would need to retain access to the journal, given that there are often limitations on how many articles they can actually lend out. Not to mention the fact that the poor interlibrary loan offices would be filling requests for way too many libraries at one time. Also copyright fees. Huge copyright fees. Anytime a library borrows more than 5 articles from one journal in a calendar year (or academic year depending upon the library) they have to report that any pay a fee. Science journals charge an absurd fee often based upon year the article was published and number of pages in the article. So a 5 page article could cost about $250-$300 in just copyright fees.
And please don’t even get me started on buying individual articles. Have you ever actually looked at what they cost per article in some of those journals? $200 to $300. A piece. Libraries may do that type of license (and yeah, it’s still a license) because they might need one to two articles a year from the journal. But if it’s an important research journal in a major field? They have to keep the subscription or be forced to pay an absurd amount per article in a year.
You…you did read that I was talking about collaborating, right?
If I need to spell out obvious aspects such as some Big Deals still running while others have already run out, this post would have turned into a book and most people would have stopped reading at the second paragraph.
If I need to spell out that “a clever combination of services” means that each service covers some papers for each institution such that none of the services needs to be perfect, the post would probably have turned into a technical manual of the usage of these services. Neither am I competent to write this, nor would anyone but those who run the services be interested in reading it.
If I need to spell out that “single-click” means that no human action is involved, I have completely misjudged the nature of those who stumble upon this obscure blog.
And please don’t even get me started on it being sooo expensive to buy individual articles. Where big deals have been dropped, downloads have gone way down (largely due to people saving their copies). I’ve updated the post with a figure that shows the massive savings of one library that did just that. So if you’re smart about it, you save a lot of money that way, even if it doesn’t work for everyone, everywhere – but for those some other service will work.
So yes, if you do it in a smart way, it’s technically feasible to use all these different services to buffer access for the few years until most of the journals have gone belly-up.
Perhaps I should mention a bit about who I am. I worked as an Interlibrary Loan librarian for 8 years at a tier 2 major research institution, bordering on tier 1 with a law school and medical school.
Interlibrary Loan is never just “single click.” There is always human interaction somewhere to make sure that the article gets to the right person and that it’s the right article. Maybe it’s one less step for you, the person filling out the request, but there’s a lot of work on the backend to make it happen. Or if you’re thinking of the Copyright Clearance Center’s version of one click, there are a lot of libraries that won’t touch that with a 20 foot pole, because they can often be worse than some of the publishers.
The figure that you linked to talks about one journal company and it’s a smaller one of the big ones and personally I’d love to know where the figure came from, because that would give a better idea of what their patron base is. It maybe that their need for that particular collection was no longer needed or was never needed vs. another publisher, such as Elsevier, being needed more. It may not seem expensive to you to buy individual articles, but there are a lot of different factors for a library to have to buy them that way.
And for some libraries/universities to bear the cost of Big Deals still running is a bit unfair. Not to mention that the publishers are going to hike up their prices to cover the increase in their usages going up as they download and send articles via ILL. Or they’ll block them from doing that. There are some publishers that don’t allow articles to be downloaded from the databases and sent via Interlibrary Loan. Or if you do there are weird requirements to do so, such as downloading the article, then printing said article, then scanning it in again, and then sending it to the library.
You’re right something needs to change. And it would be great to say that these journals will go belly up if we do something like these. But a lot of journals are owned by the same publishers now. And them going belly up would be equivalent to the major car companies all going under in the same week. Might seem like a good thing for a bit, but the long term ripples would create bigger problems.
There have to be better ways, including universities to change their requirements for tenure track positions or for professors to be promoted. A number of them still don’t support OA journals, believing them to be less rigorous. The changes have to start with administrations better understanding what need to happen to help make this happen and libraries can’t do this battle on their own.
Of course you are correct that ILL today still requires a lot of effort. Before the telegraph, getting a message across the US required a lot of effort from the Pony Express. A smart ILL resolves article requests in a way that reroutes the request to the nearest cooperating institution where there still is access and then uses the meta-data of the requested article to establish the ILL instance. If there is such a collaboration at all, of course the collaboration obviously must involves cost-sharing – or it would be a parasitic relationship, not a collaboration. That’s what “collaboration” means: you work together – not one exploits the other. Yes, I agree, that would be “a bit unfair” – but then it wouldn’t be a collaboration (at least I wouldn’t call it that and I have published on the evolution of cooperation).
Here’s the source of the figure: https://twitter.com/hildabast/status/732641033071251459
It doesn’t matter if it doesn’t work for everyone. It covers some part of the literature, while other solutions cover other parts.
While Elsevier does seem quite big for us, it’s not even close to “too big to fail”, by about 2-3 orders of magnitude, e.g.:
https://en.wikipedia.org/wiki/Too_big_to_fail#Bank_size_and_concentration
https://en.wikipedia.org/wiki/List_of_largest_companies_by_revenue
Here we’re talking several hundreds to thousands of billions US$ in revenue per bank/car company and hundreds of thousands of employees. Compare Elsevier (by far the largest publisher): 4b revenue and ~10k employees. Tiny. Heck, VW just put aside more than an entire yearly world-wide budget of subscriptions to pay for their scandal…
Thus, even if the five largest academic publishers were to go bankrupt, it wouldn’t even register as a blip in the greater economy. Even in terms of unemployment: these publishers don’t have many employees, as most work comes from us academics and/or is outsourced. The few competent employees who provide valuable services will quickly find employment in the libraries which now have plenty of money left for hiring competent experts.
But the important point isn’t if the companies themselves survive, the important thing is that the subscriptions die, because they’re trapping all the money we need for other, more modern things. If Elsevier et al. manage to shift from content-selling to service-providing, then why should we care? If we aren’t happy with their services, we switch from, say, Elsevier to Ubiquity or something.
While changing “incentive structures” is a very hip thing to ask for in these days, I don’t understand why “oh it would be so cool to have email” was sufficient in the 1980s to get a university to invest millions in a technology nobody knew, while today, we not only have to ask for perfectly validated and widespread technology, we first have to remodel the entire academic structure to get our universities to buy us the infrastructure we need for our work? What development have I missed that explains, (let alone justifies) such a massive change in protocol? In the 1980s, new technology came and academia adapted by the early 90s – we now use mostly email and submit our papers via our browser. And then all development seems to have suddenly stopped. It’s now 2016 and we still use the internet for email and to use the browser for reading and submitting. Did the people running our infrastructure (and I mean computing centers and libraries) all get collectively fired around 1995 and replaced with a technophobe cohort for the ensuing two decades? What happened that before 1995 our universities were at the forefront of innovation in IT and now they’re 25 years behind the curve?
Maybe the answer is the mindset that unless faculty changes the way academia is run and explicitly asks for the implementation of each and every individual technology everybody else is already using, that only then we will actually get said technology. Obviously, this wasn’t the case in the 1980s, because I don’t think any faculty ever asked for email. So, why was it so easy then and why is the analogous sort of thing so difficult now?
Simple: Because unless the articles in the cancelled journals have all been made Green OA by their authors, we cannot access them any more without subscriptions.
No. There are now a good half dozen other, perfectly legal ways to get cheaper access than subscriptions – provided our institutions collaborate intelligently. And then there’s SciHub which works quite well. With today’s technology and services, subscriptions are expensive convenience, but no longer required for accessing the literature. Subscriptions have become a luxury good for which I don’t think we can justify the expense any more.
You and I (1) know how to access just about any article published, Bjorn, but you and I are also the same ones who (2) have been making our own work OA for years. But institutional libraries also have to provide for the needs of that majority of their users who don’t, and haven’t.
I made the mistake (long ago) of counting on the rationality assumption. The desert years have made me more realistic. Now it’s your turn. Librarians have to keep helping their users until their users help themselves — and I don’t mean by relying on Sci-Hub (which I love, but mainly as a reductio ad absurdum of the status quo).
In other words, although I’ve conceded defeat (so far) I still think mandatory OA is the only way to a stable solution.
I’m not talking about sci-hub. The post details (now with use cases) how one could, with just a little collaborative effort, leverage an automated combination of LOCKSS/Portico, ILL, green repositories and request-offprint-button to buffer access for almost all literature for all institutional users during a transition period (not a stable solution) where we cancel subscriptions and use the freed funds to buy and implement modern infrastructure (the stable solution).
With such an effort, most users likely wouldn’t experience more than maybe a few hiccups, but they’re already used to patchy access anyway, so it wouldn’t look vastly different from what people have now. In this time, we can implement current IT that is about as superior to current publishing practice as email is superior to snail mail or skype is to the telephone. Once that transition is done, those who still want to use the equivalent of snail mail or the phone can do that – but without government subsidies.
Obviously, with subscription moneys shriveled to almost nothing, this means most journals will go extinct, with modern, online communities taking their place.
Making a distinction between commercial and society publishers would be very helpful.
Well, yes and no. Clearly, most society journals are cheaper than for-profit journals. However, many society journals are also more expensive than they need to be. In general, massive savings can be had if all our output were simply taken care of by our institutions, who go for the lowest bidder for their services. Societies then have to adjust for the lost revenue, which I think is a good thing.
The thing is we already do cost-per-use analyses every time subscriptions roll around. That cost per use is often a dollar, or maybe several dollars. If it gets near the cost to interloan it then yeah, we do start looking very closely at stopping our subscription. So for the vast majority of our subscriptions, they’re already cheaper than interloaning and significantly cheaper than pay-per-view.
In the case where someone’s cancelled a subscription and discovered that requests for articles go down, that’s not necessarily because people have found them elsewhere or don’t need them after all. It’s because you need to factor in the other cost: the time of the user. For much of research, if they can’t click the link and have the article right there right then, then it’s too time-expensive.
I’m all for Green OA, but there are a whole bunch of use cases where we systematically need the copy-of-record.
And LOCKSS only works where the license from the publisher actually gives us perpetual access.
And many of our databases we’re not paying only for content but also for the search functionality and citation metadata and APIs and integrations with other products.
And many of our databases we’re paying only for indexing because it’s the best or only way to find the content even exists because Google Scholar isn’t all that and neither even are our discovery layers.
And maybe, maybe in theory a sufficiently complex system could knit together a solution (starting with a link resolver that can find green OA; that’s a great dream) to overcome this problem for that database and that problem for this database and do it all seamlessly for the user and cheaply for the library. But creating and coding and maintaining such a complex system would be hugely expensive in staff-hours and it’s really hard to get an institution to commit to funding a whole raft of new staff positions in the hopes that in the long-term it might save money.
Thanks so much for your comment, Deborah.
Yes, getting this to work costs some money up front. I would tend to guess that it’ll cost much less then 10b/year, in particular if you calculate total cost (it’ll only run a few years – no subscriptions means to way to keep the journals running). I’d even guess that the money of one saved Big Deal will pay for all such staff, depending on the size of the collaboration, e.g., looking at the example I posted in the update.
Yes, getting this to work takes collaboration. That was one of the main points of the post: “creating and coding and maintaining such a complex system” is precisely what it took to get the internet going in the first place. Did that keep universities from not only investing in such code, but also dump millions into the necessary hardware? No it didn’t, even though the benefits were much more volatile and uncertain than the benefits of replacing subscriptions with something that actually works in 2016. Of course, in the 1980s, if anything, it was even harder “to get an institution to commit to funding a whole raft of new staff positions in the hopes that in the long-term it” will lead to everybody on the planet to use this fancy new thing called ‘electronic mail’. And yet, within a few years, institutions committed massive amounts of not only new staff positions but also of expensive hardware, with much less to hope for than yearly savings in excess of US$9b every single year.
So what was different in the 1980s that institutions collaborated to spend money on much poorer outcome expectations, such that now, even much improved outcome expectations are not enough to collaborate in such a way?
“… then ask user if they want to send copy request to author (single click) …”.
I guess one reason why the option of emailing authors for papers may still be a bit under-used is the expectation of “no success” or at least “slow success”. However, most authors are more than happy to send out their pdfs, at least in my experience. It’s just that they usually have full inboxes anyway and may not get to it immediately.
Therefore, to make the process even more efficient, wouldn’t it be a good idea to introduce some simplification at the receiving end as well?
For example, almost every email client allows automated responses. All we would need is a common, agreed-on format in the subject line. For example: “Paper request: DOI xxxx”, and the email client would automatically and immediatey send out the correct paper, then delete the request email.
Sounds a bit like a late-20th-century solution, but may work, if enough authors would sign up to it (and someone woud assemble a “How-to” for setting up automated responses in various clients).
Of course, publishers would say it was illegal…
Yes! That would indeed be a quite complicated way to get a paper, but as a last resort for a transition period, it would be perfectly fine!
I’ve always thought one way to get even the stodgy PIs on board in a hurry would be to refund some amount of the overhead the university takes from grants. Or maybe earmark some of that money to the cost of paying for articles that aren’t available.
Thanks for commenting!
Your first suggestion is already being widely used for incentivizing grant applications, at least here in Germany.
The second one is indeed worth contemplating, at least for a certain group of faculty – one needs to be careful here, not to set some new perverse incentives.
Great suggestions, thanks!
Agree 100%. As a small corporate library we have vitually no subscriptions, and run entirely on pay as you view downloads – about 850 per annum. It should be possible to cancel subscriptions, but no doubt the publishers would just raise their PAYV fees. As it is, there is quite a range of fees, and if a non-profit organisation can sell for say $20, then the $50 charged by a profit company includes a $30 mark-up. Exorbitant. But to counter it you need co-operation and the prospects of a year or two of relative chaos. Not easy on either count
No, you are right, not easy. You are also right, it cannot ever be more than just for a transitioning period, as publishers will struggle to somehow pull in the funds they used to get from subscriptions. However, with the amount of money at our disposal if we cancel/don’t renew a substantial number of subscriptions (i.e., almost all of them), we can quickly implement modern technology such that nobody would ever dream of going back to the digital stone-age we now live in. Once that is running, those few who still want to use the equivalent of the Pony Express, can do so on their own money. However, it is unlikely that the remaining journals will contain much content, if nobody can be bothered using their stone-age hassle…
At Florida State, we cancelled our Springer big deal last year in consultation with a faculty senate task force. You can learn more about it here – https://www.lib.fsu.edu/news/fsu-libraries-journal-subscription-changes
What might be interesting to the conversation above is that we have implemented a rapid interlibrary loan program for any Springer article needed by faculty, so that they can have it usually within 24 hours. There is still a cost we are eating for the ILL charges, but that is still incredibly less than what we would pay to a publisher in a big deal. Speaking of, why does ILL cost money again? Oh right, because publishers have colluded with the Copyright Clearance Center to put another access barrier there based on fear of copyright infringement.
Thanks so much for this incredible valuable information, Micah! The more I research into this, the more technically feasible it appears.