According to a recent study, employee surveillance is rampant in today’s corporate work environment. This study documents how, often under the pretense of cybersecurity or risk analysis (sort of like academic publishers, actually), companies analyze the behavioral data they collect from their employees to help them make “evidence-led”, i.e., algorithmic employment decisions. Some of the tools are used to assign risk scores to employees and to categorize them into risk groups:
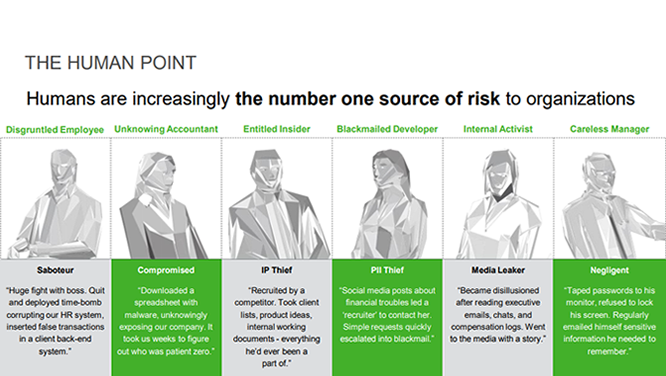
A company in ‘Workplace Analytics’ is selling a product called ‘OccupEye’ that tracks employees with movement sensors mounted under their desks. They have partnered with network giant Cisco that uses WiFi routers to derive movement patterns within rooms and buildings. Besides movement detection and text analysis, mouse-clicks and keystrokes (also as suggested by academic publishers) can be analyzed and incorporated into the algorithms as well, in order to, e.g., classify employees as “Low Performer”, “Good Performer” or “High Performer”, as Zalando is doing (p. 135 in the study).
Surely, academia would never use performance metrics for their hire and fire decisions? OK, bad joke.
Those academics who lament that not being allowed to use journal rank and other metrics to evaluate other researchers would deprive them of objective means to distinguish between applicants may very soon have all their wishes fulfilled and then some.
Ever since we calculated that only a very small percentage of what our libraries are paying publishers goes towards publishing costs and profits, many (including us) have wondered, where the rest of the money is going. Interestingly, Elsevier’s Paul Abrahams, who commented in the discussion, did not mention where their non-publishing costs accrue, but stated that their overall rejection rate was 77% at Elsevier. Using current market rates for publishing services and assuming that Elsevier does not spend more on publishing than current market rates, I calculated that publishing an average article likely costs Elsevier US$574.74 (our scenario B), i.e., very close to the estimated average per-article publishing costs for the industry:

If Elsevier’s revenue per article also were to clock in at the industry-average of around US$4,000, then each article would provide Elsevier with about US$1,200 in profits, given their profit margins of just above 30%. If our industry-average calculations really were to match the numbers of industry giant Elsevier that well, one may wonder what Elsevier is doing with the remaining US$2,200 per article that go neither towards publishing nor towards profits?
Of course, we can only guess, but for clues, one may look at Elsevier’s tweet from yesterday:
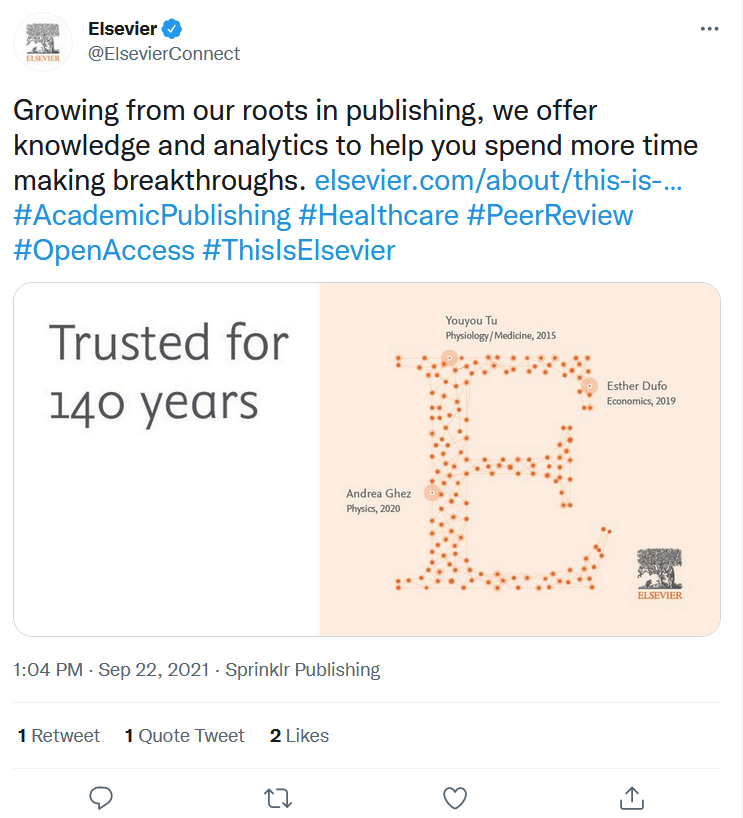
Elsevier states that “knowledge and analytics” is what they do today – publishing is only mentioned as their “roots” in the past, not something that is relevant today or, let alone, in the future. The link Elsevier promotes in that tweet points to a page on their own site where it also says: “Elsevier has really positioned itself as a data science company” and Elsevier adds right below it: “Evidence-led decisions”.

What sort of “data analytics” is used for what kind of “evidence-led decisions”, you may ask? I’m getting to that.
The acquisitions of Elsevier parent company RELX confirm this transition to “data analytics” and “evidence-led decisions”:

For 20 years now, RELX and Elsevier have invested in academic data analytics. But what kind of data are they analyzing and for which “evidence-led decisions”? Funny you should ask: they are analyzing your data of course! Here is a graph that shows what Elsevier has been buying over these last two decades when you (like me) may have been too busy fighting for #openaccess to pay attention (grey box denotes just publishing):

Whenever you interact with any of these tools, your user data is being collected and analyzed by Elsevier. After all, this is their core business, as they themselves state. Elsevier’s parent RELX is one of the largest data brokers on the planet and owns, among others, Lexis Nexis. This means that RELX can now combine your professional data with your private data and sell it. For instance, Lexis Nexis is selling their collected data and analytics to law enforcement agencies that are not allowed to collect such data themselves. Why shouldn’t Elsevier/RELX sell these data right back to academic institutions from where at least the professional part of these data has been harvested?
That may sound dystopian to some, but if you are a dean or a provost or a member in a search or tenure committee, the above may actually sound quite alluring. In that case, you may perhaps feel relieve that very soon now the possibility becomes available to license products that allow you to use not just publication records, but real-time professional and private user data to automate the classification of applicants and help you make “evidence-led” employment or funding decisions. No more need to invite anybody for interviews or be surprised by the political positions of future faculty. Moreover, you can rest assured that acquisition, development and implementation of these tools was sponsored by the tax-payer money your institution has been overspending on publishers in the past. Obviously, for you and people like you, this was money well spent! This nice fact ensures that, just like the publications in the last decades, your institution will be paying twice for such useful tools: once for their acquisition/implementation and then again, when your institution actually licenses them.
If you happen to find these possibilities enticing, all you need to do is – nothing: just let your institution keep overpaying publishers and soon the rebate offers for faculty surveillance tools will start flowing in. After all, every institution in the Netherlands has already licensed such a tool in exchange for open access publishing with, you guessed it, Elsevier. So all you need to do is sit still and wait for big brother to swing by your revered academic institution and say ‘hello’ also to you. And just in case you think only Elsevier is using our payments to expand their vertical integration, think again:

This post is probably best closed by quoting the Science Foundation Ireland who, after the Netherlands, have also partnered with Elsevier for similar reasons, it seems:
We have partnered with Elsevier, which is probably best known as a scientific publisher. They have access to a vast array of data, and this will help us to establish where Ireland is good and nearly good in emergent and convergent technologies. It will also help us decide on the actions we need to take to make us really good. For example, we might see a certain field where we are nearly good at present and find that we need to recruit top talent or run new funding calls to support it.













Comments are closed.