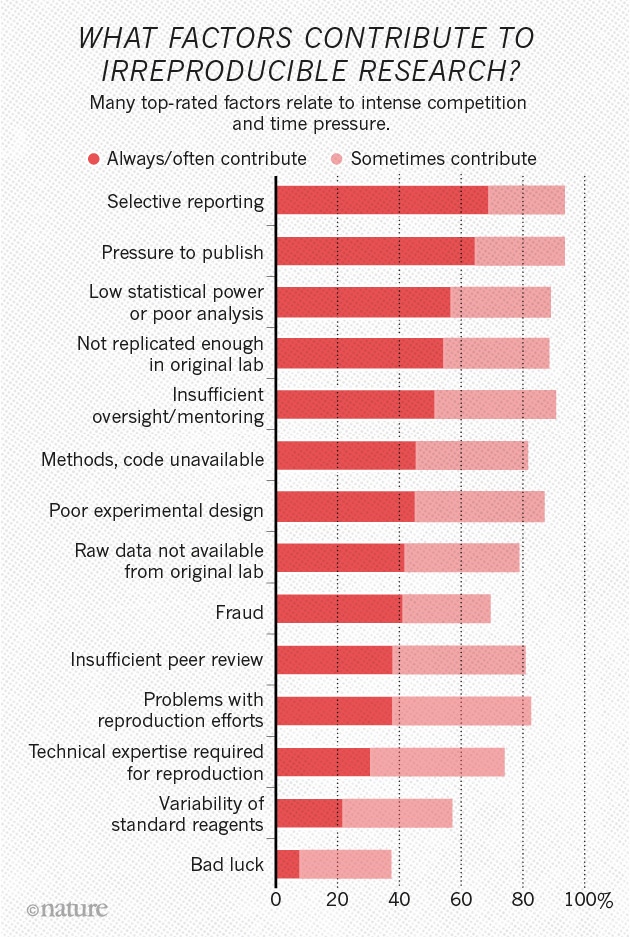
Academic publishers in general and Elsevier in particular have a reputation for their ruthless profiteering, using professional negotiators pitting hapless librarians against their own faculty during journal subscription negotiations. Consequently, these companies boast profit margins of over 40%, when the industry average for all periodicals hovers around 5%.
One strategy that has worked exceedingly well is to insult the intelligence of their customers. There are many examples, but the classic surely must be to raise prices so much, that a steep discount makes price increases of double the inflation rate look like a bargain to the cornered librarian:
As if to demonstrate the mindset of academic publishers that scholars lack the intellectual resources to see through this strategy, publisher consultant Joe Esposito felt it was necessary to explain these rather obvious shenanigans.
As outlined previously, this condescending assumption that scholars lack the neuronal wherewithal to understand and hence counteract publisher exploitation is a recurrent experience when interacting with academic publishers both in person, written and in publisher behavior. A particularly galling example among the already mentioned and linked ones are ‘green’ embargoes, i.e., that the author version of a subscription article cannot be posted until a certain period of time has passed. These embargoes are implicit admissions that without such embargoes, nobody would be willing to pay for the work the publisher has added to the author version. In other words, the publishers add nothing of value to a scholar’s work, and yet, scholars keep agreeing to publisher embargoes and keep paying obscene subscription fees. Looking at the financials of these corporations, it does not seem like this kind of behavior has hurt their bottom lines in any way.
Elsevier in particular is always a gold mine of such obvious insults of scholars. The latest point in case is their ‘vision‘ of a transition to open access. I commented that this short article manages to insult the intelligence of scholars in three different ways (click to enlarge):
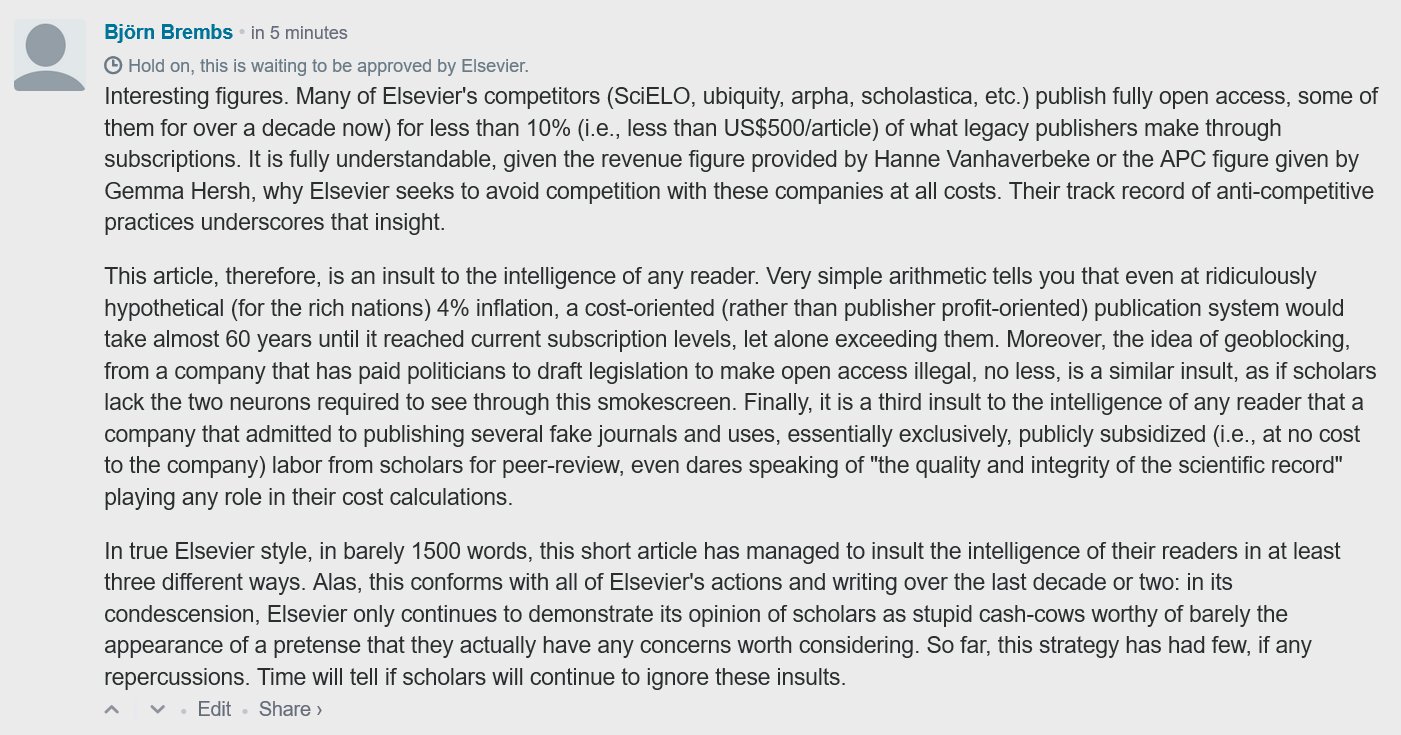
I took a screenshot, because I suspected it would not get approved by Elsevier, which of course it didn’t. [UPDATE, 04-10-2017: Apparently the comment is being held in moderation until it can be posted together with a response from Elsevier] They offered to post a redacted version which I declined. The comments that are already posted on the article before mine quite clearly show that not everyone feels insulted.
Interestingly, Elsevier quickly responded on Twitter, where I had posted the screen-shot comment. However, before I go into what aspects Elsevier did respond to, I should emphasize the much more important aspects Elsevier did not choose to immediately engage with:
- The most important aspect of the comment is that the ‘vision’ aims to increase prices, when they are already 90% over what we should be paying, if publishers wouldn’t use their monopolies to extort an obscene subscription ransom. Elsevier did not choose to engage on that front.
- What they also didn’t address first was that Elsevier has a long track record of trying to prevent or at least stall the transition to open access by various regulatory means. One constant target has been the practice of deposition of author manuscripts in institutional repositories (aka. ‘green open access). Not only are most Elsevier manuscripts under an embargo, Elsevier also paid about US$40,000 to lawmakers in the US to sponsor legislation that would make this green route to open access illegal. In their vision, they proposed another angle to hamper access, geoblocking – as if these repeated attempts at stalling or preventing access weren’t part of the public record. This consistent resistance to making anything public should be anathema to any ‘publisher’ and we as scholars are obviously too intellectually challenged to notice.
- They also did not react to my statement that they rely essentially exclusively on subsidized labor for their quality control (i.e., peer review), which means it can’t factor in as a cost. And yet, as if assuming scholars were sheepish cash cows only there to be milked for corporate profits, we should yet accept that ensuring the “quality and integrity of the scientific record” is something we should expect to pay more for than today.
Besides all of the points to potentially react to, Tom Reller, head of Corporate Relations for Elsevier, took the time to send off a tweet on this particular issue:

He was referring to the six fake journals Elsevier published until 2005 (i.e., 12 years ago, discovered in 2009). I had raised this issue in a clause referring to the integrity of the scientific record. The six fake journals were part of a stealth marketing campaign funded my Merck in the guise of peer-reviewed scholarly journals. These journals were then distributed for free to medical doctors to get them to prescribe Merck products on the basis of the purported ‘scholarly literature’. In other words, Merck paid Elsevier to publish Merck advertisements that were designed to look like scholarly journals. As if to prove that one can risks patients’ health and insult scholars by faking journals without any major consequences, the only repercussion Elsevier faced was that they had to publicly apologize in 2009, when the scandal broke. It is this apology that Mr. Reller referred to in his next tweet:
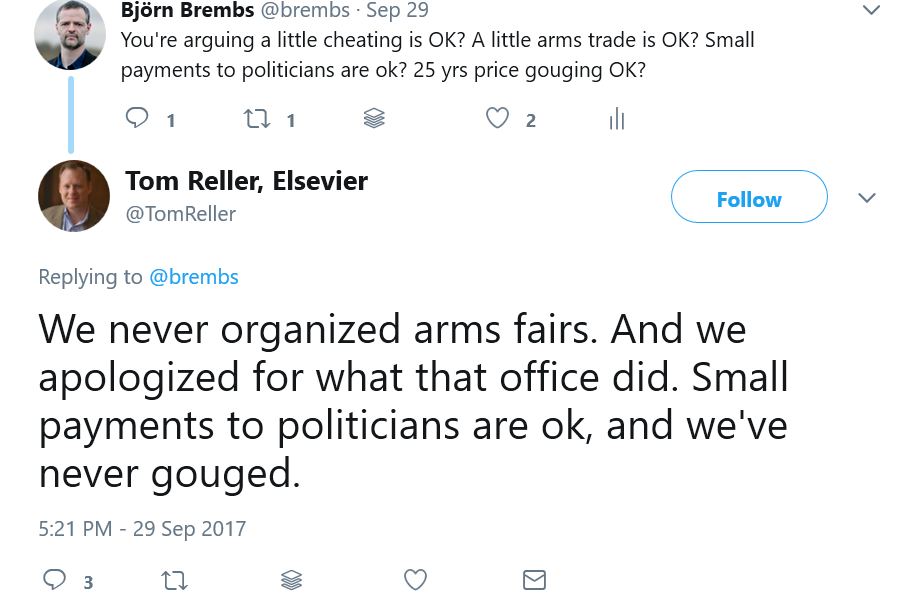
Elsevier never organized arms fairs? Well, let’s see what Google has to say about that (click to enlarge):
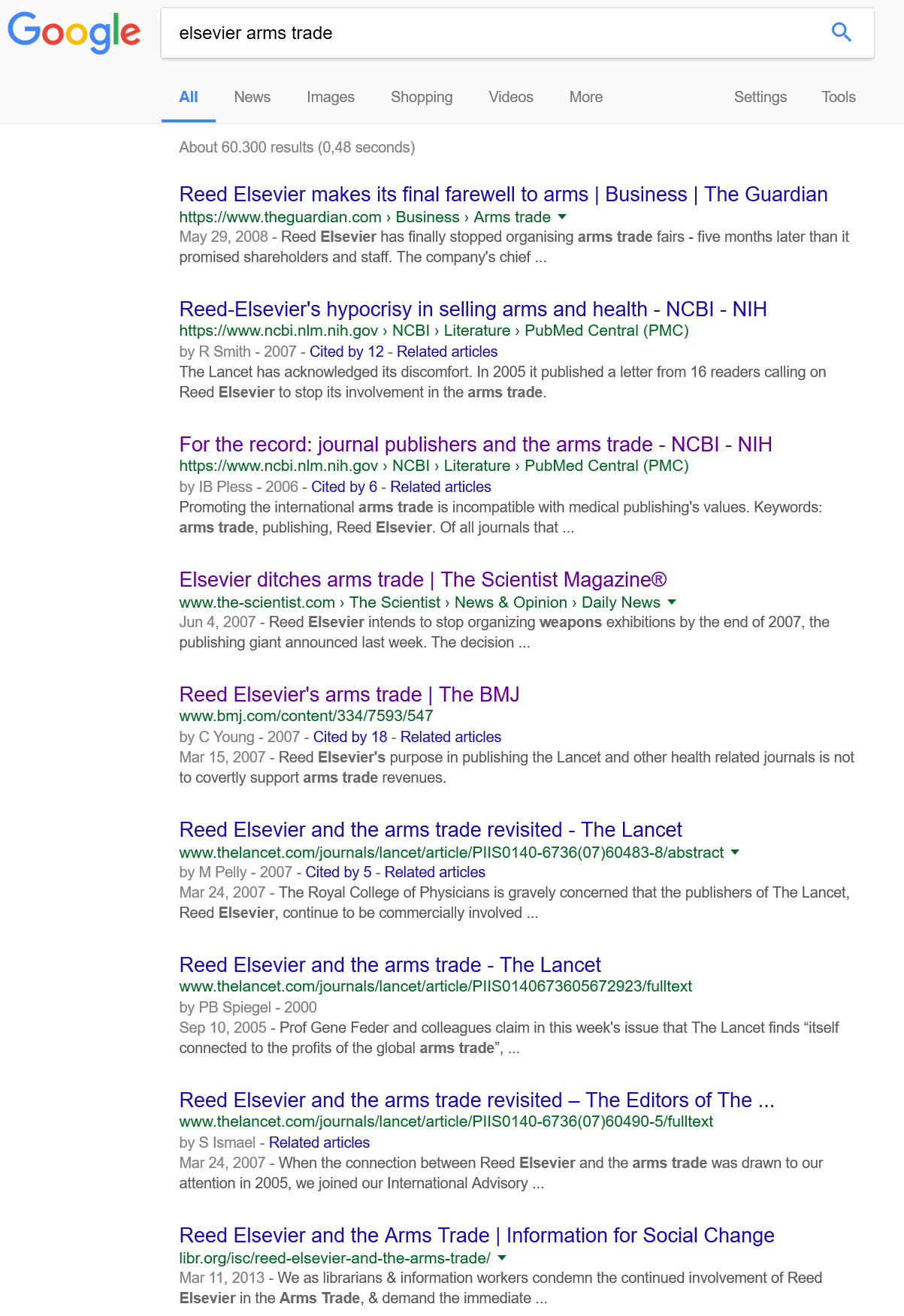
I think it is quite clear that ‘Elsevier’ shows up quite a bit when you search for “Elsevier arms trade”. However, you also see that it comes with another name, “Reed”. “Reed Elsevier” (now RELX) was the parent company of Elsevier. So technically, Mr. Reller is correct that the Elsevier branch of Reed Elsevier didn’t themselves organize arms trade: Elsevier outsourced this job to a sister company in the same corporation. I’m sure every scholar is now equally convinced as Mr. Reller that Elsevier was just as upset over Reed Elsevier boosting arms sales and simultaneously selling health journals as anybody else.
Mr. Reller also expressed the sentiment that buying politicians for small amounts of money (~US$40k in this case) to sponsor legislation that makes open access illegal is “ok”. I am somewhat more hesitant to assume that scholars cannot find anything wrong with a ‘publisher’ trying to bribe politicians into making public access illegal.
Finally, Mr. Reller is correct that Elsevier have never been convicted of any ‘price gouging’ (if this term even exists in a legal sense). In denying price gouging, however, Mr. Reller assumes scholars cannot do simple arithmetic. Elsevier’s revenue can be easily discovered, about US$3 billion. Roughly 75% of this revenue is said (reference, thanks to Christian Gutknecht in the comments!) to come from public sources, i.e., about US$2.25 billion. Mr. Reller himself tells us that Elsevier publishes about 400,000 articles annually. These numbers tell us that the public is paying about US$5625 for each Elsevier article. This is about the same amount estimated for any scholarly article world-wide. Actual costs for publishing range anywhere between less than US$100-500, depending on various factors. Thus, simple arithmetic tells us that Elsevier charges about ten times above their actual costs of making an article public. That may not fall under any jurisdiction for price gouging and Elsevier certainly never had to publicly apologize for their outrageous behavior.
Maybe Elsevier is right: scholars are stupid and will continue to oversee these insults, while Elsevier is laughing all the way to the bank?
[UPDATE: 06-10-2017] An unidentified technical issue prevented Mr. Reller’s comment from being posted, so I am posting it straight to the post instead. I don’t think it needs any additional comments from me:
Dear Björn, I’m sorry you are so disturbed by this, but your comments here and on Twitter and your blog all reflect an inaccurate view of our past and current business. For starters, there are no grounds to accuse us of anti-competitive activities. As a large player in the sector, our business practices have been reviewed in many markets (usually in the context of journal and company acquisitions), and we’ve been given a clean bill of health in every instance. The truth is, scholarly publishing is a vibrant market with lots of choices and one we’re excited to compete openly and fairly in.
On geo-blocking, there is no such proposal, nor was that the point of the piece. The piece as a whole looks at the transition to open access and where the challenges are. It is the broader questions raised in the piece that need to be addressed by all stakeholders before getting into details of what models might look like. We do, constructively and positively, propose two possible ways of helping Europe meet its ambitions for gold OA when the world is not united around one single model. But we do not go into any details around how these models might work, as there are broader questions that need to be answered first.
The Australasian fake journals you refer to were produced by between four to six employees working for a local Excerpta Medica office in Australia, outside the operation of our traditional journal business. Those were pharma marketing magazines that were common to that market, with very limited free print distribution and published prior to improvements in disclosure protocols (post Vioxx). Still, they lacked proper oversight and while they were full of sponsor’s advertisements (hardly ‘stealth’ as you suggest), they didn’t meet our global standards for disclosure, and we regretted their production (we sold the EM business for strategic reasons back in 2011).
Regarding your comment about the usage of publicly funded scholarly labor, we only charge for the content we’ve added value to. Any publicly funded content that hasn’t been voluntarily submitted to us for publication is owned by the author (or funder), who is free to disseminate it in any manner they wish. What we all have to acknowledge is that authors continue to send us and other publishers their content to treat and publish in growing numbers each year – thus, validating our value-adding activities, which includes protecting the quality and integrity of the scholarly record. Preprints are more accessible every day through the rise of preprint servers and free-to-low cost access programs.You suggest that we paid politicians, presumably referring to the US, where donations to political campaigns are commonplace, highly regulated and totally transparent. Many US universities and their trade associations also have lobbyists and political action committees. We support the election campaigns of thought leaders on many of the public policy issues we follow. American lawmakers share vastly different views on thousands of issues and draft or support legislation according to how strongly they feel about a given issue.
On your blog, you accused us of owning an arms trade fair (10 years ago), to which we pointed out that Elsevier never owned that show – a sister exhibitions business did. Associating us with that show is akin to blaming a math department for something an athletic department did. We’re all different businesses within a holding company. We all work to share back-office costs and infrastructure, but we’re not responsible for each other’s business activities. In fact, we at Elsevier deserve credit for listening to our community and convincing our parent company and sister business to exit that show.Lastly, I see you’re making various attempts at calculating actual costs vs revenues of our journals business. Such attempts will always be inaccurate as you’re not considering that we have a broadly diversified business that involves costs and revenues from a wide variety of product lines other than journals.
I don’t see how our efforts to provide more transparency into how we view the marketplace is insulting to anyone, but that’s for you to decide for yourself. I personally think suggesting we think authors and customers who use our services are stupid is well, just that. We’ll continue our ongoing dialogue with the community in the hopes that you and others will have a more accurate view of our contributions to science. Thank you.