A dedicated, non-olfactory mushroom body sub-circuit mediates the interaction between goal-directed actions and habit formation in Drosophila 926 downloads0.00 KB
We are looking for a PhD student interested in the functional, molecular and structural profile of neuronal circuits underlying learning, memory and behavior. In a 30-year research effort (lay summary, paper), we have recently identified a new gene (atypical PKC, aPKC) necessary for a form of motor learning in the fruit fly Drosophila and in which neurons it is required. The prospective PhD student will use molecular tools to identify potential interaction partners of aPKC and then use behavioral experiments as well as confocal microscopy techniques in combination with transgenics to validate and functionally characterize the role of the candidate genes.
The candidate:
The ideal candidate has a Master’s degree in a relevant field, experience in Drosophila husbandry and standard molecular cloning techniques, as well as some coding proficiency. A solid command of the English language is also important.
The position:
As is commonplace for Germany, this will be a three-year project, funded by a DFG 65% position, i.e., about 1,900€/month after tax and with full benefits, membership in our graduate schools and all the usual bells and whistles that comes with such a position in Germany. There are no lectures to attend or rotations to adhere to – just 100% of pure, unadulterated research fun. We will provide training in behavioral experiments, confocal microscopy and open science.
Our research:
Trial and error is a successful problem-solving strategy not only in humans but throughout evolution. How do nervous systems generate novel, creative trials and how are errors incorporated into already existing experiences in order to improve future trials? We use a variety of transgenic tools, mathematical analyses, connectomics and behavioral physiology to understand the neurobiology of spontaneous behavior, learning and adaptive behavioral choice.
Our lab:
We are an open science lab that prioritizes inclusion and diversity to achieve excellence in research and to foster an intellectual climate that is welcoming and nurturing. We are based at the University of Regensburg, an equal opportunity employer with over 20,000 students and more than 1,500 faculty, in Regensburg, Bavaria, Germany. Regensburg is an incredibly nice city with a high quality of life. Affordable, safe, cultural, civil, great local food, and close to other great cities like Prague or Munich.
Please send your application with your CV and a short, one page letter of motivation to my institutional address (bjoern.brembs@ur.de). Applications will be considered until the position is filled, but applications before June 1, 2024 will receive preferential treatment.
Like this:
LikeLoading...
Share this:
Posted on March 22, 2024at 14:18Comments Off on We are looking for a PhD student
A few years ago, I came across a cartoon that seemed to capture a particular aspect of scholarly journal publishing quite well:
The academic journal publishing system sure feels all too often a bit like a sinking boat. There are many leaks, e.g.:
– a reproducibility leak – an affordability leak – a functionality leak – a data leak – a code leak – an interoperability leak – a discoverability leak – a peer-review leak – a long-term preservation leak – a link rot leak – an evaluation/assessment leak – a data visualization leak etc.
A more recent leak that has sprung up is a papermill leak. What is a ‘papermill’? Papermils are organizations that churn out journal articles that are made to look superficially like research articles but basically only contain words without content. How big of a problem are papermills for science?
In many fields it is becoming difficult to build up a cumulative approach to a subject, because we lack a solid foundation of trustworthy findings. And it’s getting worse and worse.
The article states that something on the order of 10,000 articles a year being produced by papermills poses a serious problem to science. These numbers most certainly are alarming! The article also cites Malcolm Macleod:
If, as a scientist, I want to check all the papers about a particular drug that might target cancers […], it is very hard for me to avoid those that are fabricated. […] We are facing a crisis.
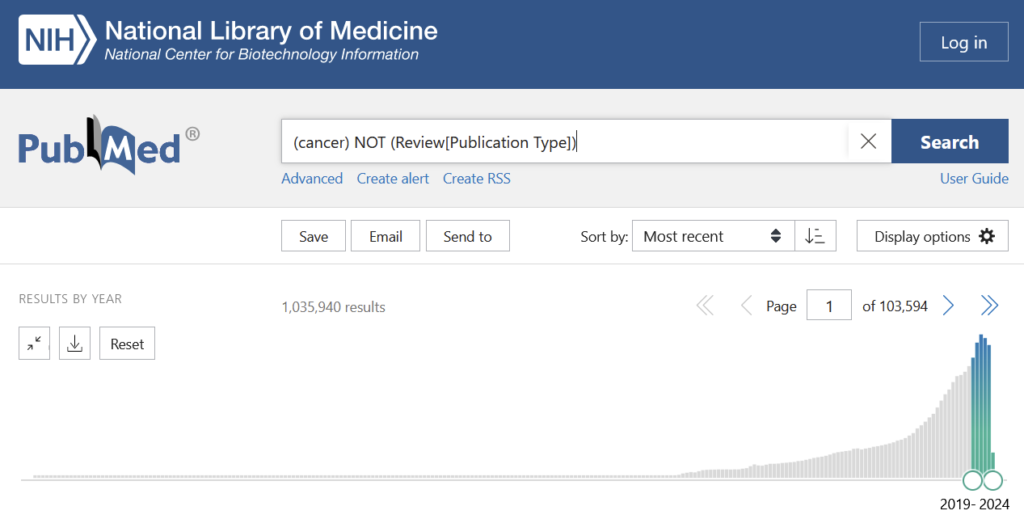
OK, challenge accepted, let’s have a look at cancer research, where the reproducibility rate of non-papermill publications is just under 12%, so we’ll round it to that figure. PubMed lists about one million papers (excluding reviews) on cancer in the last 5 years:
If the sample result of 12% were representative, this would mean that the last 5 years in cancer research produced about 880,000 unreliable publications, or about 176,000 per year. And that’s just cancer. Let’s also pick psychology, where replication rates were published as 39% in 2015. 2015 is a long time ago and psychology as a field really went to great lengths to address the practices giving rise to these low rates. Therefore, let’s assume things got better in the last decade in psychology, so after 4-5 years, maybe 50% replication was achievable. Searching for psychology articles yields about 650,000 non-review articles in the last 5 years:
This amounts to about 65,000 unreliable psychology articles per year.
So according to these very (very!) rough estimates, just the two fields of cancer research and psychology together add more than a million unreliable articles to the literature every five years or so. Clearly, those are crude back-of-the-envelope estimates, but they should be sufficient to just get an idea about the orders of magnitude we are talking about.
If the numbers hold that about 2 million articles get published every year, just these two fields would together amount to a whopping 10% of unreliable articles. Other major reproducibility projects in the social sciences and economics yield reproducibility rates in these fields of about 60%. Compare these numbers to a worst case scenario of all papermills together producing some 10k unreliable articles a year. If the scholarly literature really were a sinking boat, fighting papermills would be like trying to empty the boat with a thimble, or plug the smallest hole with a cork.
It was my freshman year, 1991. I was enthusiastic to finally be learning about biology, after being forced to waste a year in the German army’s compulsory service at the time. Little did I know that it was the same year a research paper was published that would guide the direction of my career to this day, more than 30 years later. Many of the links in this post will go to old web pages I created while learning about this research.
The paper in question contained two experiments that seemed similar at first, but later proved dramatically different. The first one was conceptually most simple: a single Drosophila fruit fly, tethered at a torque meter that measures the force a fly exerts as it attempts to rotate around its vertical body axis (i.e., trying to turn left or right), controls a punishing heat source. For instance, attempting to turn to the left switches the heat on and attempting to turn to the right switches the heat off. There is a video describing the way this experiment was set up at the time:
In the paper, my later mentors Reinhard Wolf and Martin Heisenberg described how the flies learn to switch the heat on and off themselves and how they, even after the heat is permanently switched off, maintain a tendency to prefer the turning directions that were not associated with the heat. The “yaw torque learning” experiment was born. Quite obviously, yaw torque learning is an operant conditioning paradigm, as the fly is in full control of the heat.
In another experiment in the same paper, the flies control the angular position of a set of black patterns around them with their turning attempts, pretty much like in a flight simulator (also described in the video above): whenever the fly attempts to turn, say, left, the computer rotates the patterns to the right, giving the fly the visual impression of actually having turned to the left. There are two pairs of alternating patterns arranged around the fly and one set is associated with the same punishing heat beam as in yaw torque learning, such that the fly can learn to avoid flight directions towards these patterns in this “visual pattern learning” experiment.
Like yaw torque learning, visual pattern learning appears to be an operant experiment, as the fly controls all stimuli. However, this conclusion may be premature, as the flies may just learn that one of the patterns is associated with heat, just as the Pavlovian dog learns that the bell is associated with food. Wolf and Heisenberg addressed this question by recording the sequence of pattern rotations and heat applications from one set of flies and playing it back to a set of naive flies. If the Pavlovian association of patterns with heat in the “replay” (or ‘yoked’) control experiment alone was sufficient to induce the conditioned pattern preference, the operant behavior of the flies would just be a by-product of an essentially Pavlovian experiment. However, there was no preference for a pattern in the “replay” flies, so visual pattern learning in the Drosophila Fight Simulator is still an operant experiment at its core – despite the conspicuous ‘contamination’ with a Pavlovian pattern-heat contingency.
In the course of my early studies, I was entirely oblivious of this research, until in 1994 I took a course in Drosophila Neurogenetics where I learned about these two experiments. I remembered Pavlov’s classical conditioning experiments from High School, as well as operant conditioning in Skinner boxes. Both Pavlov and Skinner having been dead for some time, I thought the biological differences between operant and classical conditioning must be well known by 1994, so I asked Reinhard Wolf during the course, if he could explain to us the biological differences between operant and classical conditioning: what genes were involved and in what neurons? To my surprise, he answered that nobody knew. He said there was some genetic data on classical conditioning and some neurons in a brain area called “mushroom bodies”, but for operant learning, nobody knew any biological process: no genes, no neurons, nothing. I was hooked! One “nobody knows” reply to a naive undergraduate question was all it took to get me set up for life. I felt that this was a fascinating research question! What are the neurobiological mechanisms of operant learning and are they any different from those of classical learning?
The following year I started working towards answering this question in my Diploma thesis (Master’s thesis equivalent). It seemed to me that to be able to tackle that question, I first needed to understand what “the operant” actually was, so I could study its mechanisms. To get closer to such an understanding, I collected a large dataset of 100 flies in each one of four experimental groups: One group was trained in visual pattern learning as described above. Another group was trained in a Pavlovian way, such that the patterns were slowly rotated around the fly such that each pattern would take 3 seconds to pass in front of the fly, such that the heat would be on for three seconds with one pattern in front of the fly and 3 seconds heat-off when the other pattern was passing before the fly. The two remaining groups received the same treatment as the two first groups, but without any heat. Both classical and operant experiments were set up such that the pattern preference after training, tested without heat, was of about the same magnitude. To achieve this, the classical experiment had to be set up that the flies received multiples of the amount of heat that the flies in the operant experiment would receive (i.e., the 3s heat-on/3s heat-off procedure). I wondered why that had to be this way? Why did operant training require much less heat than classical? I hypothesized that the operant flies may learn specific behaviors that get them out of the heat quickly or that enable them to avoid the ‘hot’ patterns more efficiently. To test this hypothesis, I fine-combed the behavior of the flies with a myriad of different analyses I coded in Turbo Pascal – to no avail. I could not find any differences in the behavior of the flies that would explain why the operant flies needed so much less heat than the classical ones. Despite there being two differences in the classical and the operant setups, i.e., more heat and no operant control in the classical experiments, there didn’t seem to be any major difference in the animals’ behavior. Obviously, I may just have missed the right behavioral strategy, but lacking any further ideas where or how to look for them, I cautiously concluded that the operant flies may somehow learn their conditioned pattern preference more efficiently when they are allowed to explore the patterns with their behavior, as opposed to slower learning when the patterns were just passively perceived – some kind of “learning by doing” maybe? Heisenberg’s pithy comment from those days is still stuck in my mind: “This is a genuine result, but at the same time, the world is full of non-Elephants.”
Despite the negative results, I enjoyed this type of research enough and found the research question so exciting that I wanted to continue in this direction. I decided to do my PhD in the same lab with Martin Heisenberg as my advisor and I was lucky he had a position available for me, so I started right after I had handed in my Diploma thesis in 1996.
In my ensuing PhD thesis, I tried to further come to grips with the fact that operant visual learning seemed to be so much more efficient than classical visual learning. My first approach was to eliminate one of the two differences in my previous Diploma work, the amount of heat the classically training animals received. I wanted the only difference between the experiments to be “the operant”, i.e., the operant control over the stimuli. I started by turning towards the “replay” experiment, where the flies passively perceive the same pattern/heat sequence that was sufficient for the active, operant flies to learn their conditioned pattern preference. But in this experiment, the passive, “replay” flies (i.e., the classically trained ones) did not show a preference, so I couldn’t really compare them with the operant flies that did show a preference. Why did the “replay” flies not learn? After all, the patterns were associated with the heat and this association was sufficient for the operant flies to learn. It turned out that by doubling the “replay” training, the “replay” flies started to show some preference, but much weaker than the operant flies. In this experiment, the only difference between the two groups of flies is the operant control, everything else is exactly identical. Together with the data from my Diploma thesis, this prompted the hypothesis that the animals may really just be learning that one pattern is “bad” (i.e., associated with heat) and the other “good”, irrespective of whether the animals learned this operantly or classically. The only difference between the operant and the classical experiment seemed to be that operant was much more effective than classical, but in all other aspects, there didn’t seem to be a difference between operant and classical learning. Could it be possible that at the heart of operant visual learning lies just a genuinely Pavlovian association between pattern and heat?
One of the hallmarks of a truly Pavlovian preference is that classically conditioned animals are able to express their preference of, in our case the ‘cold’ pattern, with any behavior, e.g., they should approach the ‘cold’ pattern and avoid the ‘hot’ whether they are, say, walking or flying. After much fiddling around with the setup (with the help of the mechanical and electronics workshops!), it turned out that to test this hypothesis, for technical reasons, I needed to combine the yaw torque experiment with the pattern learning experiment and replace the patterns with colors. The outcome was an experiment in which the flies controlled both colors and heat via their left/right choices, e.g., left turning yielded blue color and heat off, while right turning leads to green color and heat on. “Switch-mode learning” was the informal name for this procedure. Very long story short: it turned out that there really is a genuinely Pavlovian association formed in such switch-mode learning. Flies that learn that, e.g., green is good and blue is bad, can avoid the bad color and prefer the good color in a different behavior than the one that they used to operantly control the colors with. This means that there may be a fundamental difference between the operant yaw torque learning and operant visual learning: In the operant visual experiment, the operant behavior is important, but it does not play any role in what is being learned, only how. It doesn’t seem to enter into any association at all. Instead, it just seems to facilitate the formation of an essentially Pavlovian stimulus-stimulus association. In contrast, in the yaw torque learning experiment, there isn’t anything else that the animals could possibly learn, but their own behavior. In a way, yaw torque learning is a ‘pure’ form of operant learning, while operant visual (i.e., pattern/color) learning is ‘contaminated’ with a very dominant Pavlovian component. Both are operant experiments, but what the flies are learning looked likely to be dramatically different. Would that difference also affect the biology underlying these learning processes?
In the light of these results, I concluded my thesis work with a study on some classic (pardon the pun) Pavlovian phenomena. I had mixed feelings towards my achievements so far. On the one hand it felt like I got a bit closer to understanding the commonalities and differences between operant and classical learning, but I certainly hadn’t been able to find any genes or neurons involved in operant learning. Some reviewers of the work emphasized this shortcoming.
After graduating in the year 2000, I moved for my postdoc to Houston, Texas to study another form of ‘pure’ operant conditioning in an animal where we could get access more easily to the neurons that are involved in the learning process, the marine slug Aplysia. There I learned how the biochemical properties of a neuron, important for deciding which behavior will be generated, change during operant learning and how this leads to more of the rewarded behavior. This work was like a booster to my initial curiosity about the biological mechanisms of operant learning. More than ever before I felt that it now was high time for new approaches to discover which genes work in which neurons in Drosophila operant learning.
As mentioned above, for Drosophila classical conditioning, several learning mutants had been isolated decades earlier. After moving from Texas to Berlin in 2004, we tested them in our “switch-mode” operant color learning experiment. Consistent with the idea developed in my PhD work that such operant visual learning is essentially just an operantly facilitated Pavlovian learning task, some of these mutants are also defective in operant visual learning – likely because the Pavlovian ‘contamination’ is so dominant, as the previous experiments had suggested. How would these mutants fare if we took the colors away such that the ‘contaminated’ “switch-mode” became ‘purely operant’ yaw torque learning? To my surprise, the mutant flies did really well! The first of these experiments weren’t actually done by me, even though they had been on my to-do list for years by then, but by an undergraduate student – I only replicated them a few months later. These results made it unambiguously clear that there really was more than a conceptual difference between operant yaw torque learning and operant stimulus learning: there was a very solid biological difference. If there was a stimulus to be learned, i.e., a “Pavlovian contamination”, then Pavlovian learning genes were involved, but once that contamination was removed, Pavlovian learning mutants did just fine in the resulting ‘pure’ operant learning task. While this work was done with the mutant rutabaga, which affects a cAMP synthesizing enzyme, the results from a different gene were even more surprising: flies where the function of the protein kinases of the “C” type (protein kinase C or PKC) were inhibited, behaved in exactly the opposite way: they did fine in visual learning but failed in the ‘purely operant’ yaw torque learning task. This work took four years and in 2008 we published that we had found a gene family specific for operant learning, PKC.
So by that time, some 14 years later, I had a first answer for the initial question that got me started in the first place: there is a biological difference between operant and classical learning and you only see it if you remove all “classical contamination” from the operant experiment. Now that we had a gene family, what we needed next was one or more (as many as possible, really) individual genes and the neurons they are expressed in. It turned out to be quite difficult to find out which of the six PKC genes in Drosophila is the one important for yaw torque learning. Julien Colomb, a postdoc who had joined me in Berlin, used both mutants and RNAi approaches but was only able to rule some of the PKCs out, but did not find the crucial one. Things looked a bit better on the front where we tried to identify the neurons: Whichever PKC it was, it was apparently important in motor neurons. That may not sound so odd, after all, we are conditioning a behavior and motor neurons control the muscles for the behaviors. But these motor neurons were located in the ventral nerve cord (the “spine” of the insects) and we had thought operant conditioning was something that needed to involve the brain. So while the results were rather clear, I nevertheless didn’t value them sufficiently, as I was convinced the brain was more important than the ventral nerve cord, no matter what these experiments tried to tell me. There probably was a good explanation for these results, I thought then, once we find out what is really happening in the brain. The results were what they were and we published them in 2016.
While these experiments were ongoing, another candidate gene had appeared on the horizon, the transcription factor FoxP. The background for this candidate goes back to 1957 and the book “Verbal Behavior” by BF Skinner. In the book, Skinner claimed that the way we learn language looked an awful lot like operant learning: trying out phonemes until auditory feedback tells our vocal system that we have indeed said the words we wanted to say. This seemed like rats trying out behaviors in a Skinner box until they have found out how to press the lever for food. Or, I thought, how flies try out behaviors until they have found out how to control the heat with their yaw torque. While these all really did seem to look very analogous on the face of it, this view was shredded already in 1963, in a book review by Noam Chomsky, then a young scholar. But this critique not only helped catapult Chomsky to fame, it was also one of the starting points of what later was called the “Cognitive Revolution”. One of Chomsky’s most hard-hitting arguments was that the analogy was simply a false analogy and that Skinner had not provided any real evidence at all. A few years before his death, Skinner acknowledged the criticism and agreed he did not have any evidence other than the observed superficial parallels. In 2001, a gene was identified that would bring this classic academic feud back into public focus. A mutation in the human transcription factor FOXP2 was identified as the cause for a very specific speech and articulation impairment, verbal dyspraxia. A few years later, one of my colleagues in Berlin, Constance Scharff and her team knocked down the same gene in their zebrafinches and got an analogous phenotype: the birds had trouble learning their song. By then I was electrified! If Skinner had been right and Chomsky wrong, then there was a chance that FoxP really may be an operant learning gene. In 2007, I asked Troy Zars (who died way to soon some years later) at a meeting if he knew whether flies had a FoxP gene at all. It turned out he already had a set of mutants in his lab and was willing to collaborate with us on this project. Within a few weeks of the mutants arriving, the data started to emerge that we finally had found a single gene involved in yaw torque learning – and it couldn’t have been a more Skinnerian gene! In operant visual learning, the mutants did fine, just like the flies with the inhibited PKCs. After some additional experiments to make sure the results were solid, the work was published in 2014. It really started to look as if yaw torque learning shared more than just a conceptual similarity with vocal learning in vertebrates. It now appears the biological process underlying these forms of learning evolved in the last common ancestor of vertebrates and insects, some 500 million years ago.
Our next experiments started to capitalize on this discovery. In 2012, I had become a professor in Regensburg and a few years later, one of my grants on this research question got funded. So we hired two PhD students to help me. One of them, Ottavia Palazzo, created a suite of genetic tools manipulating the FoxP gene and the neurons where it was expressed. Among other things, it turned out that FoxP was also expressed in motor neurons in the ventral nerve cord, the neurons where PKC was required for yaw torque learning. The work started in late 2017 and in the following year, a sabotage case, where a (likely mentally ill) postdoc in the lab kept damaging (and eventually destroyed) some of our equipment, brought most of these experiments on operant learning to a screeching halt. Soon after we had unmasked and fired the saboteur (which took the better part of another year), the Covid19 pandemic started, making everything even tougher on everyone. We managed to publish the work we had done with FoxPin December 2020. By that time, the gene scissors CRISPR/Cas9 had become really useful for genetic manipulations. Ottavia Palazzo had already used them to create the FoxP tools and the second graduate student on the grant, Andreas Ehweiner, now “CRISPRed” some PKC genes we hadn’t been able to properly test, yet, and struck gold. It turned out, the atypical PKC (aPKC) was the PKC gene we had been looking for all these years! If you knocked aPKC out in FoxP neurons, yaw torque learning was severely impaired. So now we had two individual genes involved in operant learning.
This was a strong indication that FoxP and aPKC may act in the same neurons for yaw torque learning to work. A quick analysis of the expression patterns of the two genes suggested overlap in a specific set of motor neurons in the ventral nerve cord, namely the ones that control the angles of the wings to, e.g., create left- or right-turning yaw torque, the “steering motor neurons“. At the same time, we could not find any overlap between aPKC and FoxP in the brain at all, suggesting that the neurons we were looking for definitely did not reside inside the brain. Some other of Andreas’ experiments also seemed to confirm that. Now all of the evidence we had pointed away from the brain and to the steering motor neurons in the ventral nerve cord. So was it really them? To quantify which of these neurons actually expressed both aPKC and FoxP, collaborator and motor system expert Carsten Duch in Mainz, painstakingly dissected all the tiny muscles that are attached to the wing hinges and then analyzed which of the individual motor neuron terminals on the muscles showed the markers for both genes. He discovered that it really was just a very circumscribed subset of the steering motor neurons that expressed both genes and not all of them. Specifically, the neurons involved in generating the slow torque fluctuations were were conditioning in our yaw torque learning experiment were the ones expressing both genes and those involved in, e.g., fast body saccades, or thrust or roll, did not express both genes. All of this pointed to these specific neurons, but so far, it was only circumstantial evidence. What we needed to do now was to find some way to check if the aPKC/Foxp-dependent plasticity, as we suspected, was really taking place in these steering neurons and not by some bad luck in some neurons we hadn’t on our radar. It was 2023, and genetic lines that would allow us to target just the specific steering motor neurons for slow torque behavior and none of the others were just in the process of being generated, so there really wasn’t a perfect way for a genetic experiment just yet.
So we tried to come up with some other way to get more data on whether all the evidence that was pointing towards these neurons really was sufficient, or if there was some alternative explanation for our data that we hadn’t thought of. It hadn’t escaped our notice that the function of the motor neurons we were eyeing had been described in the context of optomotor responses. The optomotor response is an orienting behavior evoked by whole-field visual motion. Its algorithmic properties entail that the direction of the whole-field coherent motion dictates the direction of the behavioral output (e.g., leftward visual stimuli lead to turning left, and rightward visual stimuli lead to turning right). The currently available evidence suggests that this visual information, in flies, gets transmitted directly from the brain to the steering motor neurons via a set of descending neurons in the brain. With the brain being ruled out as a site of aPKC/FoxP-dependent plasticity, the steering neurons were the only conceivable overlap between optomotor responses and yaw torque learning. This meant that if yaw torque learning altered the steering neurons in some way, we may be able to detect this plasticity by some change in the optomotor response of the trained flies. Or, phrased differently, if we were to detect effects of yaw torque learning in the optomotor response after operant training, this would be very strong evidence that the plasticity we were looking for indeed was taking place in the steering motor neurons.
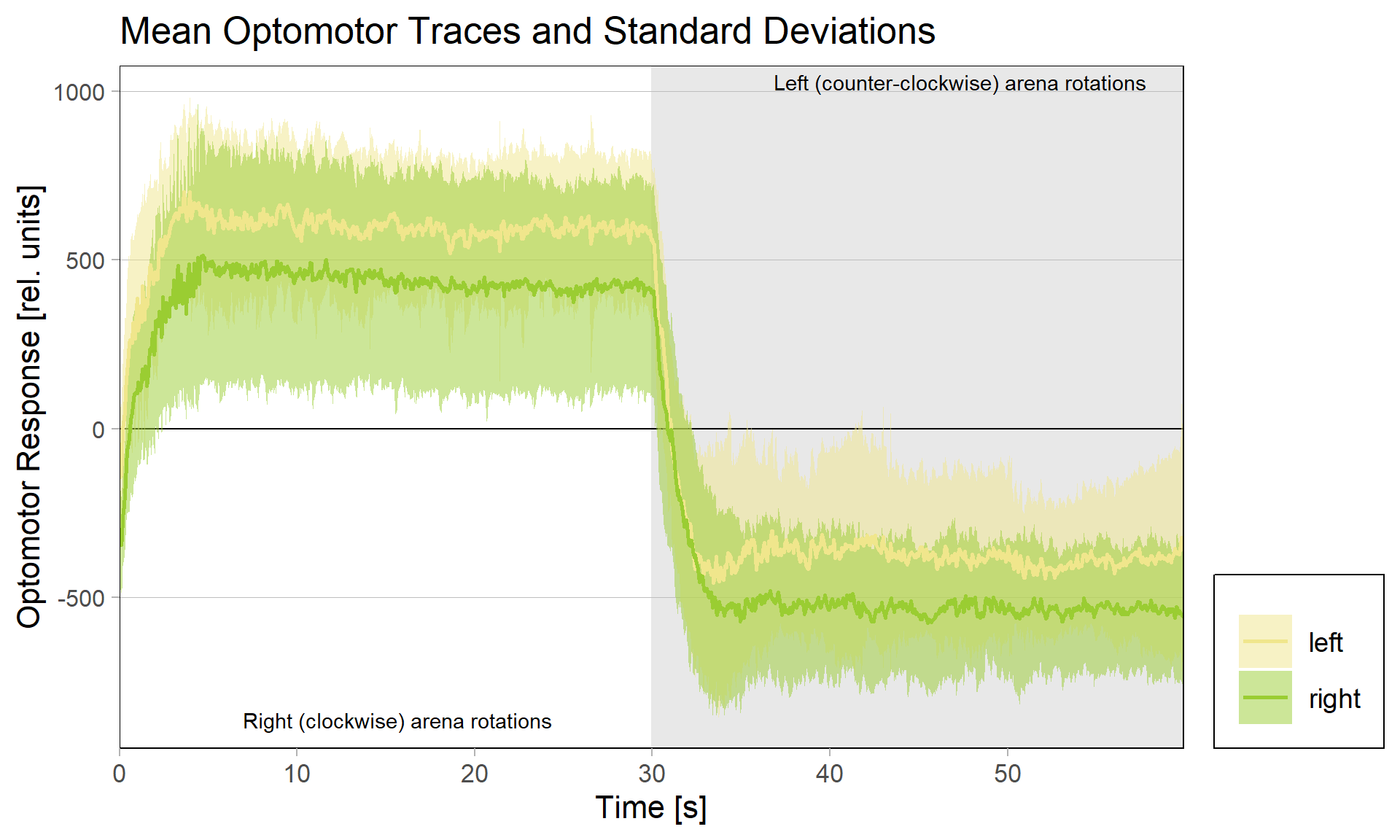
We tested this hypothesis by comparing optomotor responses before and after yaw torque learning. We found that the optomotor responses to visual stimuli that elicit responses in the turning direction previously not associated with the heat did not change. However, responses to stimuli that elicit optomotor responses in the punished direction were selectively reduced. The figure below shows the torque traces after training, separated into those flies that were punished on left-turning (yellow) and those punished on right-turning. Reference, untrained amplitudes are just over 500 units of torque, as one could guess from the respective unpunished directions in each group. Always the torque amplitude of the punished direction is reduced, i.e., right (clockwise) rotations elicit reduced torque in flies punished for right turning attempts (green), compared to the same responses in flies punished for left-turning attempts (yellow) and vice versa for counter-clockwise rotations.
These results showed that indeed the plasticity seems to happen in the motor neurons that innervate the steering muscles generating large torque fluctuations – so pretty much at the very last stage. The changes in optomotor responses after torque learning only explain about 30% of the variance in the torque data. This means that there are flies that show, e.g., strong preference for the unpunished turning direction, but only a weak reduction in optomotor response on that side, as well as flies that, say, show a strong reduction in optomotor response, but only a weak preference for the unpunished turning direction. This means that there are very likely additional mechanisms at play, but, at least for now, these mechanisms do not seem to depend on aPKC/FoxP. As of now, this seems difficult to reconcile with the observation that knocking out any one of aPKC or FoxP completely abolishes yaw torque learning to undetectable levels, but this is what future research is for.
Today, almost exactly 30 years after a seemingly simple question when I was an undergraduate, we are finally in the process of localizing mechanisms of plasticity for “Skinnerian”, operant learning to specific neurons and specific genes. Now we can finally begin to really exploit the vast toolbox of Drosophila neurogenetics on a much larger scale than before to find the remaining parts of the puzzle: Which other genes are involved in this pathway? What are the biochemical and physiological changes in which parts of the neurons that give rise to the behavioral changes? How does yaw torque learning interact with visual learning to make it happen faster – aka the “learning by doing” effect? Why do “classical” learning mutants learn yaw torque better? How is this “Skinnerian” learning regulated, such that it is faster under some conditions (like when there are no colors present, i.e., pure) and slower under others (i.e., when the experiment is “contaminated” with Pavlovian colors)?
On the one hand, it seems the future has now become more boring, because it is so clear what experiments have to come next. In the past, I never knew what experiments to do until the current experiment was done. Too much was unknown, too few conceptual principles understood. Now, one just needs to open the Drosophila toolbox and there are enough experiments jumping at you for the next decade. On the other hand, the future has never been more exciting: I never have felt that the future promised any major advances – it was all too uncertain. Now that we have the first genes and the first neurons, it feels like the sky is the limit and that the next research questions will be answered dramatically more quickly than ever before.
Only now, looking back 30 years after having started from essentially zero, it is dawning on me that, building on the early behavioral experiments of Martin Heisenberg, we have now managed to open up a tiny little research field with a huge potential. The genes we found indicate that the biological processes we study is at least 500 million years old and present in most animals, including humans. It appears to be involved not only in language learning, but also more generally in many other forms of motor learning. And there are few other preparations around anywhere, in which these processes can be studied both in such splendid isolation and how they interact with other learning processes as in, e.g., habit formation. The only problem is, I likely won’t have another 30 years to capitalize on the efforts of the last 30 years: mandatory retirement in Germany will hit me in just 15 years from now. Humans surely live too short for the speed of this kind of research.
Like this:
LikeLoading...
Share this:
Posted on January 11, 2024at 15:55Comments Off on The speed (or lack thereof) of science
You may have seen a neutered version of this post over at the LSE blog. This post below, however, puts the tiger in the tank, as it was enhanced by CatGPT:
Maybe scholarly societies have taken “the instruction”follow the money!” a tad too literally? There now are societies that make 83% of their nearly US$ 700 million in revenue from publishing (American Chemical Society). Or 88% of US$130 million (American Psychological Association). Or 91% of US$5 million (Biochemical Society). In essence, societies like these (there are hundreds, especially in STEM fields) are publishers first and societies second (or fifth). One could be forgiven if one imagined their business meetings involved chanting, “Publish or Perish” while stacking green taller than a Himalayan cat tower. But wait, there’s more! Some of these organizations even side with corporate publishers against scholarship, e.g., when litigating against organizations or individuals striving to make research more accessible, or when begging wannabe-authoritarian rulers to protect their archaic, parasitic business models. Can it still be considered ethical to charge multiples of the publication costs of an article in order to finance executive salaries, subsidize member dues, sponsor prizes, host all-you-can-drink receptions at annual meetings or pay lawyers to ensure nobody can read the works of your scholars? Who needs scholarly integrity when you can have lucrative deals and lawyers on speed dial?
This cat-astrophic prioritization becomes even more absurd if one researches the role such societies have played in purr-suing their primary mission as ‘societies’: supporting scholars in making connections to like-minded individuals, exchanging ideas and promoting their respective fields of scholarly interest – in short ‘socializing’. For some of these ‘societies’ their mission apparently involves as much of such scholarly socializing as a hermit cat on a deserted island. There is a reason these organizations were called “societies” before they became publishers. The root of their names contains their essential function, as described in 1660 for one of the first such societies, the Royal Society: “Their first purpose was no more, then onely the satisfaction of breathing a freer air, and of conversing in quiet one with another, without being ingag’d in the passions, and madness of that dismal Age”. And isn’t it ironic that these very societies, born in an era of intellectual enlightenment, seem to have missed the memo about social media’s advent over 15 years ago? Were they chasing cash like a cat the laser dot or were they too busy debating the financial advantages of ink and parchment versus parchment and ink?
Is it possible that maybe one reason these scholarly societies missed the social media boat, is that their noses were buried too deep in financial spreadsheets to realize that there was a technology in the making that not only was about to transform the way their mission was going to be supported, but even shared the root of their names? Shouldn’t these bastions of scholarship, if they truly cared, have embraced FriendFeed or Facebook in their kittenhood back then? But why stir the litterbox, when there’s a chance it might disrupt the cash flow? Maybe many felt the threat such #icanhazpdf-technology may pose to their bottom line so acutely, they failed to envisage the opportunities it provided for their members? Was one reason why there was no huge movement from within the scholarly societies to be involved in the development of technology so central to the raison d’être of societies, that not enough of them actually cared sufficiently about scholarship any more? Each scholarly society is different and many have more or less belatedly embraced social technologies in one way or another now. However, it appears as if this engagement has only rarely exceeded the use of corporate platforms as broadcasting tools, rather than as a social technology that encourages, promotes and protects social interactions among scholars and with the general public.
Today, we have technology that allows scholarly societies to make good on past mistakes and show their true colors: the ‘fediverse’ provides tools and technologies that are ideally suited to finally bring scholarly societies out of their digital caves and into the 21st century. One of these is Mastodon, a decentralized social technology. While some scholarly institutions, including some societies, have started to implement their own Mastodon instances, the large majority still appear as as bewildered as a cat presented with a Rubik’s cube, struggling with their favorite corporate broadcasting platform formerly known as Twitter now having devolved into a racist misinformation cesspit.
Scholarly societies that take their mission and role for scholarship seriously have developed a keen understanding of social technologies, are using them not just for broadcasting but for scholarly exchange and to facilitate social interactions such as debate, discussion and critique among all persons interested in their research, not just their dues-paying members. The different local and federated timelines in Mastodon allow seamless interactions both within the society and outside of it, federation choices enable societies to choose which content purr-fectly matches their instance and they become the moderators of their own social media presence, instead of having to rely on the whims of billionaires. Where are the societies that see this opportunity in giving, e.g., marginalized groups within scholarship a voice in a town square protected by scholarly rules? Rather than being relegated to obedient mice for AdTech-based surveillance platforms, societies now have the opportunity (again!) to become the designers of a new kind of digital scholarship while at the same time contributing to protecting the privacy of scholars. Due to the open source nature of the Fediverse and the widespread digital competence in the scholarly community, there is ample potential for societies to take a central role in developing a new scholarly commons and integrate this social layer into the more formal literature as part of the “open, interoperable, not-for-profit infrastructures” the Council of the EU science ministers has recently called for.
Of course, their handling of social technology is just a litmus test for how seriously a learned society is taking its role in our modern world and what perspective it has taken with regard to scholarship more generally. It appears as if scholarly societies that are still genuinely interested in pursuing their core mission are as elusive as finding Schrödinger’s cat both inside and outside its box simultaneously. Instead, the majority seem more concerned with securing and protecting sufficient publication income to maintain five, six figure salaries for their execs.
So, to the scholarly societies out there, here’s a challenge: step up, embrace Mastodon (and any of the other cool fediverse options like peertube, owncast, writefreely, hubzilla, etc.), and give those faux-societies a run for their money. Show us you’re all about scholarship, not just financial catnip!
The DFG is a very progressive and modern funding agency. More than two years ago, the main German science funding agency signed the “Declaration on Research Assessment” DORA. The first point of this declaration reads “Do not use journal-based metrics […] as a surrogate measure of the quality of individual research articles, to assess an individual scientist’s contributions, or in hiring, promotion, or funding decisions.” Last year, the DFG joined the Coalition for Advancing Research Assessment” CoARA and sits on their Board. The CoARA principles also emphasize: “Abandon inappropriate uses in research assessment of journal- and publication-based metrics”. In their position paper from last year, the DFG states in two places in the executive summary:
the assessment of research based on bibliometrics can provide problematic incentives
and
A narrow focus in the system of attributing academic reputation – for example based on bibliometric indicators – not only has a detrimental effect on publication behaviour, it also fails to do justice to scholarship in all its diversity.
In a world in which impact factors and other bibliometric measures still reign supreme, these are laudable policies that set the DFG apart from other institutions. In fact, these steps are part and parcel of an organization with a long tradition of leveraging its power for good scholarly practices. Even before DORA/CoARA the DFG has continually evolved their policies to minimize the effect of publication venue on the assessment of applicants.
Given this long and consistent track-record, now complemented by two major official statements, one could be forgiven to think that applicants for funding at the DFG now feel assured that they will not be judged by their publication venues any longer. After all, journal prestige is correlated with experimental unreliability, so using it as an indicator clearly constitutes “inappropriate use of journal-based metrics”. With all this history, it came as a shock to many when earlier this year, one of the DFG panels deciding which grant proposals get funded, published an article in the German LaborJournal magazine that seemed to turn the long, hard work of the DFG in this area on its head. The panel starts by making the following statements (my translation of sentences 2-4):
Our panel evaluates grant proposals in all their dimensions and one such dimension is the qualification of the applicant by their publication record. In a changing [publication] landscape, it is not easy to choose the right journal for the publication of research results. In this regard, we would like to share some thoughts, such that your publication strategy may match the expectations of decision-making panels.
It seems obvious that in this order, these sentences send this message:
We decide grants by looking at publication records
You better follow our guidelines of where to publish if you want to meet our expectations (and that of other panels) to get funded.
Which is pretty much the opposite of what DORA and CoARA are all about and what the DFG says in their own position paper. Or, phrased differently, if this article were compatible with DORA, CoARA and the DFG position paper, neither of the three could be taken seriously any more. At the time of this writing, the DFG has not publicly responded, neither to personal alerts about the article, nor to DORA and CoARA which have also contacted them. At the very least, the DFG does not see the article as worrisome enough for a swift response – and this is troubling.
One less worrisome explanation for this slow reaction could be that this is just one panel in a large institution and the DFG has more important things to worry about. After all, both their position paper and in their press release, they support the plans of the EU Council of science ministers’ proposal to fund an open scholarly infrastructure instead of monopolistic publishers, i.e., the plan is to have this infrastructure replace academic journals. This is obviously a major undertaking and one that also requires research assessment to change. So maybe, with limited resources, the DFG is prioritizing the larger goal over mere research assessment? This explanation does not seem very likely: last week, the news broke that the DFG plans to join the recent DEAL agreement with data analytics corporation Elsevier. Similar to the article by the panel, this contract also embodies pretty much the opposite of DFG’s own stated goals, in this case one of establishing “open access infrastructures located at research organisations that operate without publication fees payable by authors and are not operated for profit.” The many reasons why entering this contract is a mistake have already been listed elsewhere. Here, the important aspect is that this decision would be already the second time this year that DFG practice is in direct opposition to their policies.
What could possibly be the reason for this sudden and very recent inconsistency between officially stated policies and actual practice at the largest German funder after so many years of very consistent development? Apparently, it was the DFG’s Board, led by president Katja Becker (since 2020), that forced the decision to join the Elsevier DEAL over the objections of expert committees. What could possibly have motivated the Board to side with the corporate giant Elsevier against not only their own scholarly expertise, but also their own public policies?
Both DORA/CoARA, if widely implemented, would weaken the stranglehold corporate publishers exert over public knowledge and as such would help pave the way for a publicly owned, not-for-profit scholarly infrastructure for said knowledge. With this overarching goal in mind, the public statements by the DFG are internally consistent over many years and appear competent, logical, coordinated and scholar-led. In this regard, the DFG sets an example for funding agencies world-wide. In fact, the EU-supported CoARA was, in part, designed to help support the plan by the EU science ministers for a scholarly infrastructure avoiding corporate vendor lock-in. All of this constitutes a paragon of evidence-based policy-making and stands to negatively affect current corporate publishers. As such, it is safe to assume that these corporate publishers interpret these public policies of the DFG as another threat to their parasitic business model. From this perspective, both the admonition to publish in “good” journals (read: in journals predominantly published by corporate publishers) and the decision to join the Elsevier-DEAL are decidedly publisher-friendly, propping up the status quo and delaying any modernization. Why would the DFG-Board, then, act in such a publisher-friendly way, when the DFG public policies are anything but?
Nobody but the Board members themselves can know this, of course. However, in the last few days, individuals with personal knowledge have been privately pointing to connections between the DFG president, Katja Becker, not only with Stefan von Holtzbrinck (whose company not only owns SpringerNature but also DigitalScience), but also with Elsevier CEO Kumsal Bayazit. Given the DFG’s public policies, both would be expected to voice strong opposition, when given a chance to speak in private with the president of the DFG, one would suppose. Or, alternatively, has the DFG become such a big and unwieldy organization that simply the left hand doesn’t know any more what the right hand is doing? Whatever the reason, this sudden inconsistency is troubling and the potential consequences pernicious. Many applicants, at least, would probably sleep better if this inconsistency were resolved.
Like this:
LikeLoading...
Share this:
Posted on November 29, 2023at 13:32Comments Off on German funder DFG: Why the sudden inconsistency?
It’s the time of the year again where 30,000 neuroscientists head to the US to talk neuroscience. This year the big annual conference is in Washington, DC, one of the three cities able to host this large event.
Our first poster will be up on Tuesday morning and shows results from operant self-stimulation experiments using optogenetics and dopaminergic neurons. Some of this work is already available as a preprint, but this poster contains essentially all the work done after that manuscript was peer-reviewed. This poster will be presented by our Bachelor student Luisa Guyton:
The second one is on Wednesday morning and all about motor learning and the different ways how we can use genetic manipulations to improve motor learning. This poster will be presented by our postdoc Radostina Lyutova:
Klick on the posters to download the PDFs.
Like this:
LikeLoading...
Share this:
Posted on November 7, 2023at 10:29Comments Off on Heading for #SfN23 with two posters
No matter how well-intended (and we all know to which place the road leads that is paved with good intentions!), transformative agreements (such as DEAL in Germany) are generally the wrong tool at the wrong time for making publicly funded science accessible to the public. If you count public statements, the picture of a rare academic consensus emerges: the DEAL-incompatible proposals and criteria from the Council of EU Science Ministers were enthusiastically welcomed by a wide range of scientific organizations. This was not surprising as these conclusions originated from within the scholarly community and build on existing solutions within scholarly institutions. More surprising is the positive feedback coming from the smaller publishers. They welcome these modern concepts from the scientific community that have found their way into the EU decisions, because they finally give them an opportunity to compete with the larger publishers. In short, the only ones still considering DEAL to be up to the task are DEAL themselves and the big publishers; all other relevant actors who have made public statements so far, all reject DEAL.
If DEAL needs to be rejected in general, the Elsevier DEAL needs to be rejected with particular fervor. In addition to the reasons mentioned above, the price negotiated by DEAL with Elsevier is many times more expensive than the market-based solutions favored by all other stakeholders. These spiraling costs will eventually eat into the budget also of non-DEAL fields, which have already taken massive hits by the serials crisis. Elsevier is also part of the surveillance corporation RELX and the clauses in the contract that are intended to protect users from data abuse are useless, because they are neither policed nor enforced. This blank check issued to Elsevier makes participating institutions accomplices in the corporation’s eventual privacy violations. Especially in times of globally growing autocratic tendencies, there should be no question that German universities ought not to denigrate themselves to data suppliers for international intelligence services and law enforcement agencies – all important RELX customers.
A continuation of DEAL in general, but especially a DEAL with Elsevier, is therefore neither in the interest of science, the scientific institutions, the scientists, nor the public that finances them. It is only in the interests of Elsevier and those DEAL employees, who will be offered lucrative positions at the publishers after the contract is signed. Rarely has there been so much agreement in academia: There must be no Elsevier DEAL. With the opt-in procedure of this DEAL contract, every institution is now faced with the choice of whether to position itself for or against this consensus in science.
Below are the fully referenced 14 reasons why no German institution should sign the brokered (botched, really) DEAL with Elsevier:
In May, the EU science ministers clearly explained why “transformative agreements” (TAs) like DEAL are not in the spirit of science and what should be used in science instead: “interoperable, not-for-profit infrastructures for publishing based on open source software and open standards, in order to avoid the lock-in of services as well as proprietary systems, and to connect these infrastructures to the EOSC”. DEAL does not meet a single one of these criteria.
These insights are supported by recent data showing that TAs like Plan S or DEAL unfortunately do not transform, but consolidate. TAs transform nothing but public funds into dividends. The transformation process is never completed because it affects a popular business model, which is why coalitionS came to the conclusion that only 1% of the journals they examined were actually transformed, while more than two thirds missed the Open Access criteria to such an extent that they were removed from the program.
Ten major science organizations, representing most of the scientific institutions and scientific excellence in the EU, welcome the decisions of the science ministers and emphasize how groundbreaking they are (EUA, Science Europe, LIBER, ALLEA, AERG, MCAA, Eurodoc, cOAlition S , OPERAS, ANR). One of these organizations is the European University Association EUA. Their full members have already rejected DEAL in principle, via their EUA membership.
Here in Germany, the DFG is also one of the official supporters of the Council of the EU’s decisions. The largest research funding organization and central self-governing institution for science in Germany has recognized how “trend-setting” the decisions of the science ministers are and also emphasizes how important it is to establish “open access infrastructures that operate without publication fees paid by authors and without profit intentions”. DEAL is diametrically opposed to these goals.
The Council of the EU’s decisions follow long-formulated demands from the scientific community. Just recently, ten international experts highlighted how long overdue this modernization of scientific information infrastructures has become.
The infrastructure units of the scientific community also emphasize that they are ready to implement the infrastructure recommended by the Council of the EU. The Coalition of Open Access Repositories (COAR) emphasizes in particular that a large part of the infrastructure already exists to implement the Council’s decisions.
The small and medium-sizedpublishers damaged by DEAL also welcome the Council’s decisions, as their implementation promises an actual market that would replace the secret DEAL negotiations with the large monopolists.
Elsevier is part of the surveillance corporation RELX, which has signed contracts with several intelligence services, so institutions with civil clauses need to take an even more critical stance. In principle, a university should protect the privacy and academic freedom of its members and not act as a willing provider of user data. In this respect, institutions which enter into a contract with Elsevier may face legal jeopardy and the risk of liability for libraries associated with DEAL is likely substantial.
The clauses intended to protect user data and privacy in the DEAL contract with Elsevier, are neither policed nor enforced and therefore invalid. Elsevier de facto has full access to users’ private data and those affected are under the obligation to prove any damage.
The DEAL with Elsevier will be significantly more expensive than the negotiated prices suggest. For one, APCs rise supra-inflationary. Moreover, Elsevier forces its journals to publish more articles in order to increase sales.
The DEAL was negotiated even though there are alternatives for publication services that can be tendered, so the contract violates procurement rules.
Profit-oriented companies cannot dictate public institutions what research they are allowed to conduct. The AI ban in the DEAL with Elsevier represents a violation of (in Germany constitutionally protected) academic freedom.
Overall, the DEAL project itself does not gain in trustworthiness if members of the DEAL project group sign up with one of the publishers even before the ink on the contract has dried.
Jeffrey “predatory journals” Beall famously catapulted himself out of any serious debate with an article in the journal TripleC, entitled “The Open-Access Movement is Not Really about Open Access“. In it, Beall claimed that OA proponents don’t care about access, but that they form an “anti-corporatist movement that wants to deny the freedom of the press to companies it disagrees with”. The article is so replete with similarly unhinged fairy tales that Beall quickly lost all standing with the scholarly community.
Seasoned science policy developer Robert-Jan Smits may just have published a similarly devastating article. Granted, the comparison of Smits to Beall is hugely unfair: In contrast to Beall, Smits has an outstanding track-record: architect of the EU Horizon 2020 program, director-general of research and innovation (RTD) at the European Commission, spearheading the Plan S initiative, to only name a few. Likely, no single article can have a major impact on such a stellar career. Especially because of Smits’ expertise, experience and competence, his recent Research Professional News article “Plan S: Stay the course” (also on ScienceBusiness), is raising a number of flabbergasting concerns. Some quotes:
The case for open access became utterly clear when the Covid-19 virus spread rapidly across the globe, and the science community was mobilised to look for medication and vaccines. From day one, research results and data were shared and made available in real time by both academia and industry to win the race against the clock. And the commercial publishers took their responsibility by joining in and abolishing their paywalls. It would have even been unethical if they would not have done so, with certainly a public outcry as a result.
Actually, the publishers to a large extent only formally ‘published’ what had already been published as preprints before. If anything, in contrast to Smits’ claims, the Covid-19 pandemic is widely seen as an example how science can thrive without the involvement of commercial publishers.
new open-access publishers and platforms have entered the market and, as such, widened the landscape of services and enhanced competition.
It has been established for several decades now that academic publishing is not a market and that the kind of competition that does exist is not really the kind of competition commonly associated with a “market”. It is difficult to understand why someone with Smits’ level of competence still perpetuates this myth of a market.
Only 31 per cent of all cancer-related publications are openly accessible.
This figure seems to assume that public access to cancer research would benefit cancer patients. However, cancer research is only reproducible to just under 12%. Having much of this unreliable research accessible only to experts at funded institutions could be interpreted as a public health measure. This paragraph is one of many statements by Smits over the years where he appears to endorse an “open access at all costs” attitude. With regard to notoriously unreliable medical research, maybe the cost aspect should be considered more carefully? Talking about costs:
While the costs of subscription range between €4,000 and €9,500 per article, the costs of open-access publishing APCs is on average €2,500 per article, although there are of course exceptional cases whereby APCs of almost €9,000 are charged. Yet it has to be acknowledged that over recent years there has been an inflation of APCs.
These numbers and their juxtapositions are really strange. There is a very common number that has held surprisingly constant over the years, that the average cost of a subscription article is between US$4000-5000. It is nearly impossible to compute a range, as one would need to know the total subscription income for the single journals, which is a notoriously difficult to know number for all but the smallest publishers/journals. For small journals, per-article-costs are often very high, sometimes even absurdly high, see,. e.g., the New England Journal of Medicine, where each research article would cost about US$300,000. Given the average cost of a subscription article, subscriptions per-article range is probably best estimated at between almost zero and 300k – not a very useful range and far from what Smits wrote.
The price of about 2500€ for an OA article is fairly accurate, but he conveniently leaves out that publishing costs are less than half that price. With that in mind, a >100% markup doesn’t seem like such a fair price any more. Add to that the admission that APCs are increasing (arguably at a similarly supra-inflationary rate as subscriptions) and the number of published articles keeps increasing, the total cost of publishing research OA exponentially increases, making APC-OA an even less sustainable option than subscriptions. Smits goes on about costs further down:
The often-heard claim that diamond open access is free to all stakeholders distracts from the reality that there is always a price to be paid for quality open-access publishing
But he never mentions what that price is: we know that it is less than half of even current average APCs. Is he endorsing such price gouging only because it is less bad than subscription-based price-gouging?
perhaps most importantly, the transformative agreements mentioned above have not yet delivered and in many cases are not really transformative.
and immediately below that:
be ruthless about the 2024 deadline for the transformative agreements to have delivered
So Smits claims that TAs don’t work, so we must keep going with the TAs? Not sure what to make of that.
And if the bottleneck is the increasing price of APCs, just put a cap on them
Smits does not explain how that cap should be implemented. He doesn’t mention any laws being passed (in what countries?) to make high APCs illegal, so one can only assume he is referring to the Plan S idea to simply not reimburse authors for more than a fixed amount. Such a cap has been in place in Germany for nearly 20 years now and it has not had any effect on prices, as authors simply pay the amount exceeding the cap from other sources. Not sure why such an important piece of evidence seems to have escaped someone with Smits’ experience.
It was therefore very disappointing that in the Council of the EU’s conclusions of 23 May, Europe’s science ministers, while being unambiguous about their support of open access, hardly mentioned Plan S, but called for the support of “not-for-profit open-access publishing platforms and models”. With this, they take a ‘left turn’.
This ranks very high on the list of most problematic paragraphs of the article. The Council of the EU’s conclusions of 23 May have been widely heralded as a major policy advance and have been roundly welcomed from allcorners of the scholarlylandscape, even by some smaller publishers and, notably, by cOAlition S. With his statement, Smits is alone in siding with the corporate publishers who are now all but isolated from all other stakeholders. Is Smits trying to make a political statement by “left turn”? If so, his notion of a “price cap” seems hard to reconcile with a right-wing ideology, his statement that there existed a market with competition and even more so with his later statement:
It was also surprising that the science ministers gave the impression with their conclusions to wish to exclude the large commercial publishers, which provide a quality service to the science community. These key players in the world of scientific publishing just need to be forced to change their business model and embrace open access at a fair price.
And this is what Plan S is all about.
The EU Council conclusions explicitly mention the importance of preventing the kinds of corporate lock-ins which are a main driver behind the current academic crises related to infrastructure. Smits’ previous quote lamenting these conclusions together with this statement seem to imply that lock-in by corporate monopolists is precisely what Smits is defending here. A public, non-profit infrastructure, with substitutable for-profit service providers, for instance, is one option to prevents such lock-ins. If “left turn” is a political reference, then Smits finds actual competition with substitutability in a genuine market to be more to the left, politically, than his position, where the government actors in cOAlition S would be forcing corporations to change their business models and impose artificial price caps, while maintaining the corporations’ monopolist position. Where is the reason in such an argument?
I also wonder what evidence Smits has used to base is statement on that the corporate publishers provide “provide a quality service to the science community”. The most prestigious journals are all in corporate hands and the higher the prestige, the lower the reliability of the research published there. This evidence seems to suggest that getting rid of the corporate publishers and their hierarchy of expensive journals, if anything, should increase the quality of science.
Very little makes any sense in this article of a seasoned, competent, yes, even renowned policy maker. This is concerning on a number of levels. What could possibly bring someone who for decades very prominently sided with science, to become the only one left defending the corporate monopolists?
On May 23, the Council of the EU adopted a set of conclusions on scholarly publishing that, if followed through, would spell the end for academic publishers and scholarly journals as we know them. On the same day, the adoption was followed by a joint statement of support by the largest and most influential research organizations in Europe. At the heart of the goals spelled out in the conclusions and the statement of support is the creation of a “publicly owned and not-for-profit” infrastructure for scholarly publications.
Specifically, the Council
ENCOURAGES Member States and the Commission to invest in and foster interoperable, not-for-profit infrastructures for publishing based on open source software and open standards, in order to avoid the lock-in of services as well as proprietary systems, and to connect these infrastructures to the EOSC
This echos almost verbatim our proposal from 2021 where we outline a replacement for academic journals. In this post, we detail the reasons behind this seemingly radical proposal:
A vicious cycle of three crises. With their supra-inflationary price increases, profit-maximizing journals overcharge (via subscriptions or article processing charges) institutions by a factor of up to tenfold, extracting library budgets with little if anything left for infrastructural development. The resulting lack of infrastructure funds is a crisis of affordability: institutions cannot afford to invest in technology and its human support system that could relieve researchers of clerical tasks such as manuscript submission, data deposition, code publication, etc. This results in a functionality crisis that entails researchers lacking time, functionalities and human support both for efficient scrutiny during the review process as well as for making their own research open and reproducible. Not shown: Journals have apparently not invested their surplus into reviewer support, resulting in little improvement over the last decades, such that researchers are still lacking basic functionalities such as, e.g., comments via authoring system, direct author communication, AI-assisted error and fraud detection, efficient manuscript submission, etc., contributing to the functionality crisis. As the journals keep increasing their prices without a concomitant rise in investments, they fuel the replicability crisis.
This vicious cycle has been allowed to go on for so long, that more and more experts are now calling for precisely such a disruptive break. The time for small, evolutionary steps has passed and the parasitic publishing corporations have shown little willingness over the last decades even to just mitigate, let alone solve the problems caused by their extractive business models. For more than a decade, an ever-growing group of researchers have called to cut out these parasitic middle-men. It now finally seems as if our arguments have been convincing. Everything in the Council’s conclusions reiterates what the open science community has been fighting for in all this time: vendor lock-in needs to be broken, scholarly governance established and fragmenting silos replaced with interoperable, federated infrastructure.
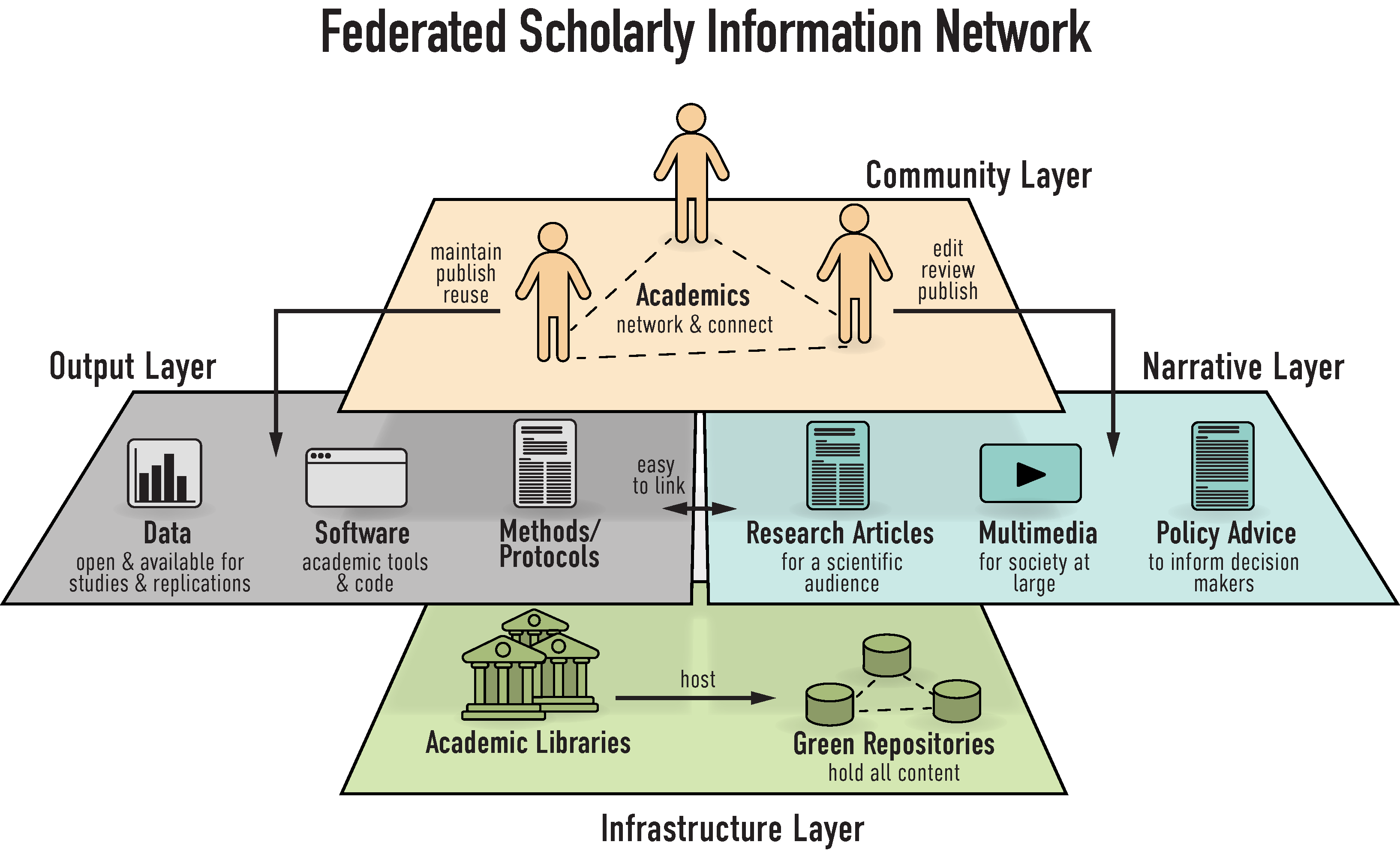
The technical solutions needed for this modernization from 17th century journals to 21 century digital technology are plenty and readily available off the shelf. Scholarship has the choice of either picking pre-existing solutions such as CORE or ORC, or design a new network. In either case, the general structural design of such a network may look something like this:
Concept for a federated scholarly information network. A federated network of institutional repositories constitutes the underlying infrastructure. Ideally, this infrastructure is designed redundantly, such that large fractions of nodes may go offline and the remaining nodes still provide 100% of the content. Users only directly interact with the output and narrative layers. The output layer contains all research objects, text, data and code. The narrative layer combines research objects in various forms, including research articles. The community layer encompasses standard social technologies such as likes, follows and other network tools (see also “Mastodon over Mammon“). Modified from LSE.
Picking an existing solution such as CORE or ORC comes with the advantage that little new development has to be done and that it is obviously very cheap: everything is already in place and only needs to be expanded. The downsides are that the existing solutions have been designed in the current ecosystem and that may have entailed some historical baggage one would need to identify and fix. Conversely, picking off-the-shelf components to build a replacement from scratch costs more, but has the advantage to be able to build a state-of.the-art system with all the bells and whistles from the ground up. It’s a bit like the choice between buying a used or new car or house.
Obviously, right after the declaration came out, the corporate misinformation machine sprang into high gear. I won’t repeat the misleading, false or sometimes just comically desperate attempts at smearing an obviously well thought-through, sound and logical solution that has been decades in the making. Suffice it to say, there are plenty of reasons why the plans outlined by the Council have drawn such widespread support from all corners of the research community, while the only resistance comes from the monopolistic corporations. This declaration tackles the root of the replicability, affordability and functionality crises. It aims to treat the disease, not the symptoms and has the potential to develop into an effective vaccine against parasitic businesses striving to leech the public purse. Little wonder these businesses fear it so much.
Data broker RELX is represented on Twitter by their Chief Communications Officer Paul Abrahams. Due to RELX subsidiary Elsevier being one of the largest publishers of academic journals, Dr. Abrahams frequently engages with academics on the social media platform. On their official pages, Elsevier tries to emphasize that they really, really can be trusted, honestly:
In fact, if one searches for “trust” with Elsevier, one may be forgiven for getting the impression that Elsevier is obsessed with trying to appear as if they were trustworthy:
For anyone following Elsevier’s endless list of transgressions, is not difficult to understand this obsession: academics routinely call the company “Evilsevier” for more reasons than there are bits on the internet (see, e.g., their Wikipedia page). With so many parasitic or outright hostile actions consistently directed at academics and academic institutions over decades, it really is prudent to at least try and provide an outwardly trustworthy face to the unsuspecting early career researcher who may not have heard of ‘Evilsevier’, yet. A wolf in sheep’s clothing:
The fact that Elsevier fits the consensus definition of a “predatory publisher” so well is thus only one of many reasons why data kraken Elsevier is so reviled in the academic community, but a reminder of it seems to have triggered the “we really can be trusted, honestly, this time” wolf-in-sheep-clothing-reflex in the RELX CCO Dr. Abrahams, such that he responded:
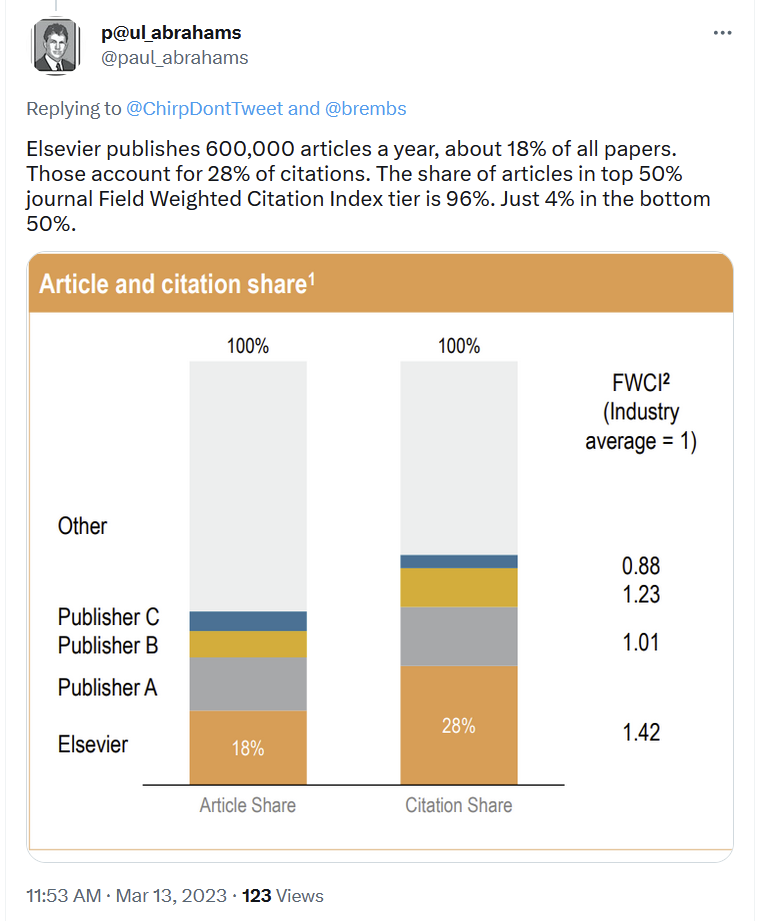
Apparently, he tried to make the claim that so many researchers author in and cite Elsevier journals that this must be evidence they trust Elsevier. He went on to make three very specific claims, which are worth examining:
As Paul Abrahams is tweeting in his capacity as “Chief Communications Officer at RELX”, let’s fact-check his three statements, one by one, as an example of just how trustworthy such public statements from RELX/Elsevier can be.
1. “Elsevier provides above-average quality…”
Let’s pretend, for now, RELX were not chiefly a surveillance platform and data broker enabling ICE mass deportations (some quality!), but instead an academic publisher (via subsidiary Elsevier) with above average overall impact (according to the citation numbers Dr. Abrahams posted himself, see above). In that case, given the negative relation between impact/prestige and quality, the available data suggest that Elsevier actually provides *below average* quality. So the first statement is contradicted by the available evidence. Of course, it may also be that Elsevier journals aren’t as impactful as their CCO claims, in which case his previous statement would be false. Either way, both cannot be correct at the same time.
2. “…for below average prices”
From the Q&A on occasion of the release of the latest 2022 RELX financial statement, and from Dr. Abraham’s tweet above, we learn that Elsevier published 600,000 articles the past year yielding a revenue of 2,909 £ million. Accordingly, an average article from Elsevier cost the tax payer 4,848£ or US$5,850. Which, even if one assumes the upper bound average cost of an article at US$5,000, is more than average. Also the second statement can be easily falsified, this time using RELX’s own numbers.
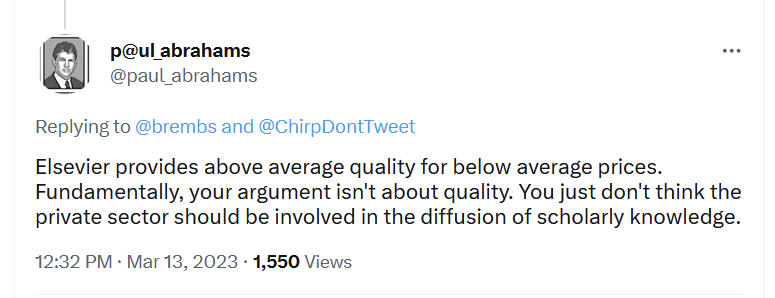
3. “You just don’t think the private sector should be involved in the diffusion of scholarly knowledge.”
Let’s take a recent article on the topic with me as a co-author and check the abstract: “It [the journal replacement] needs to replace the monopolies of current journals with a genuine, functioning and well-regulated market. In this new market, substitutable service providers compete and innovate”. Quite demonstrably, we argue for a market and the article text clearly states “traditional businesses” as competing as service providers in this market. So also this statement is obviously false. Interestingly, Paul “Chief Communications Officer at RELX” Abrahams seems to interpret our proposal of a “genuine market” as a threat to their monopoly and rightfully so: an actual market does threaten Elsevier’s gargantuan profit margins (37.8% in 2022, see above financial statement) with competition, something they fear deeply, as they have never had to deal with it in the history of their company. Quite apparently, Elsevier fear the mere proposal of competition so much, they attempt to smear it with misrepresentations by the Chief Communications Officer of their parent company.
So all three statements by the CCO of RELX turned out to be demonstrably false. Not surprising for the most reviled corporation in academia, where probably one of the least damning qualities is that they also fit the consensus definition of a predatory publisher. If Paul Abrahams keeps his job (as one would strongly suspect), it only serves to confirm that such false statements are part and parcel of the strategy with which RELX communicates with academics – and that one should never assume any engagement with them will be in good faith.