Lately, there has been some public dreaming going on about how one could just switch to open access publishing by converting subscription funds to author processing charges (APCs) and we’d have universal open access and the whole world would rejoice. Given that current average APCs have been found to be somewhat lower than current subscription costs (approx. US$3k vs. US$5k) per article, such a switch, at first, would have not one but two benefits: reduced overall publishing costs to the taxpayer/institution and full access to all scholarly literature for everyone. Who could possibly complain about that? Clearly, such a switch would be a win-win situation at least in the short term.
However, what would happen in the mid- to long-term? As nobody can foresee the future with any degree of accuracy, one way of projecting future developments is to look at past developments. The intent of the switch is to use library funds to cover APC charges for all published articles. This is a situation we have already had before. This is what happens when you allow publishers to negotiate prices with our librarians – hyperinflation:
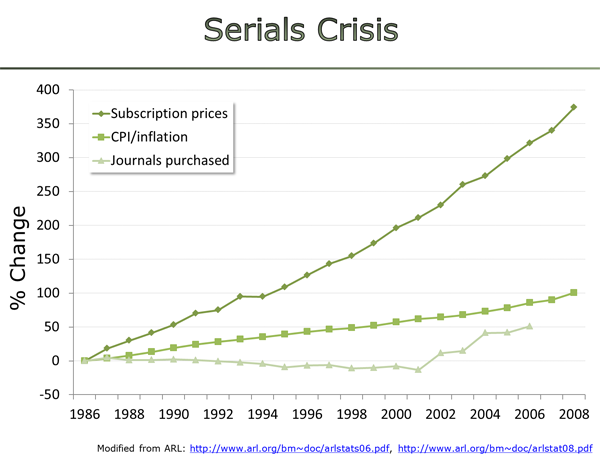 Given this publisher track record, I think it is quite reasonable to remain somewhat skeptical that in the hypothetical future scenario of the librarian negotiating APCs with publishers, the publisher-librarian partnership will not again be lopsided in the publishers’ favor.
Given this publisher track record, I think it is quite reasonable to remain somewhat skeptical that in the hypothetical future scenario of the librarian negotiating APCs with publishers, the publisher-librarian partnership will not again be lopsided in the publishers’ favor.
I’m not an economist, so I’d be delighted if there were one among the three people who read this blog (hi mom!), who might be able to answer the questions I have.
The major players in academic publishers are almost exclusively major international corporations: Elsevier, Springer, Wiley, Taylor and Francis, etc. As I understand it, it is their fiduciary duty to maximize the value for their shareholders, i.e., profit? So while the currently paid APCs per article (about US$3k) seem comparatively cheap (i.e., compared to currently US$5k for each subscription article), publishers would not be offering them, if that would entail a drop in their profit margins, which currently are on the order of 40%. As speculated before, a large component of current publisher revenue (of about US$10bn annually) appears to be spent on making sure nobody actually reads the articles we write (i.e., paywalls). This probably explains why the legacy subscription publishers today, despite receiving all their raw material for free and getting their quality control (peer-review) also done for free, still only post profit margins under 50%. Given that many non-profit open access organizations post actual publishing costs of under US$100, it is hard to imagine what else other than paywall infrastructure would cost that much, given that the main difference between these journals are the paywalls and not much else. By the way, precisely because the actual publishing process is so cheap, the majority of all open access journals do not even bother to charge any APCs at all. There is something beyond profits that makes subscription access so expensive and any OA scenario would make these costs disappear.
So let’s takes the quoted US$3k as a ballpark average for future APCs on a world-wide scale. That would mean institutional costs would drop from the current US$10bn to US$6bn annually world wide. Let’s also assume a generous US$300 of actual publishing costs per article, which is considerably more than current costs with arXiv (US$9) or SciELO (US$70-200) or current median APCs (US$0). If this switch would happen unopposed, the publishers would have increased their profit margin from ~40% to around 90% and saved the tax payer a pretty penny. So publishers, scientists and the public should be happy, shouldn’t they?
Taking the perspective of a publisher, this scenario also entails that the publishers have wasted around US$4bn in potential profits. After all, today’s figures show that the market is worth US$10bn even when nobody but a few libraries have access to the scholarly literature. In the future scenario, everyone has access. Undoubtedly, this will be hailed as great progress by everyone. After all, this is being used as the major reason for performing this switch right now. Obviously, increased profit margins from 40% to 90% is seen as a small price to pay for open access, isn’t it? Wouldn’t it be the fiduciary duty of corporate publishers to regain the lost US$4bn? After all, why should they receive less money for a better service? Obviously, neither their customers (we scientists and our librarians), nor the public minded an increase in profit from 40% to 90%. Why should they oppose an increase from 90% to 95% or to 99.9%? After all, if a lesser service (subscription) was able to extract US$10bn, shouldn’t a better service (open access) be able to extract 12 or 15bn from the public purse?
One might argue that this forecast is absurd, the journals compete with each other for authors! This argument forgets that we are not free to chose where we publish: only publications in high-ranking journals will secure your job in science. These journals are the most selective of all journals. In the extreme cases, they only publish 8% of all submitted articles. This is an expensive practice as even the rejected articles generate some costs. These journals are on record that they would have to charge around US$50,000 per article in APCs to maintain current profits. It is hence not surprising that also among open access journals, APCs correlate with their standing in the rankings and hence their selectivity:
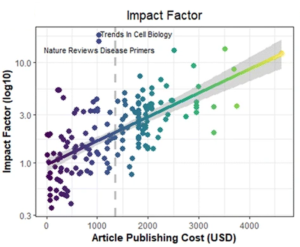 It is reasonable to assume that authors in the future scenario will do the same they are doing now: compete not for the most non-selective journals (i.e., the cheapest), but for the most selective ones (i.e., the most expensive). Why should that change, only because now everybody is free to read the articles? The new publishing model would even exacerbate this pernicious tendency, rather then mitigate it. After all, it is already (wrongly) perceived that the selective journals publish the best science. If APCs become predictors of selectivity because selectivity is expensive, nobody will want to publish in a journal without or with low APCs, as this will carry the stigma of not being able to get published in the expensive/selective journals.
It is reasonable to assume that authors in the future scenario will do the same they are doing now: compete not for the most non-selective journals (i.e., the cheapest), but for the most selective ones (i.e., the most expensive). Why should that change, only because now everybody is free to read the articles? The new publishing model would even exacerbate this pernicious tendency, rather then mitigate it. After all, it is already (wrongly) perceived that the selective journals publish the best science. If APCs become predictors of selectivity because selectivity is expensive, nobody will want to publish in a journal without or with low APCs, as this will carry the stigma of not being able to get published in the expensive/selective journals.
This, to me as a non-economist, seems to mirror the dynamics of any other market: the Tata is no competition for the Rolls Royce, not even the potential competition by Lamborghini is bringing down the prices of a Ferrari to that of a Tata, nor is Moët et Chandon bringing down the prices of Dom Perginon. On the contrary, in a world where only Rolls Royce and Dom Perignon count, publications in journals on the Tata or even the Moët et Chandon level will only be ignored. Moreover, if libraries keep paying the APCs, the ones who so desperately want the Rolls Royce don’t even have to pay the bill. Doesn’t this mean that any publisher who does not shoot for at least US$5k in their average APCs (better more) fails to fulfill their fiduciary duty in not one but two ways: not only will they lose out on potential profit, due to their low APCs, they will also lose market share and prestige. Thus, in this new scenario, if anything, the incentives for price hikes across the board are even higher than what they are today. Isn’t this scenario a perfect storm for runaway hyperinflation? Do unregulated markets without a luxury segment even exist?
One might then fall back on the argument that at least Fiat will compete with Peugeot for APCs, but that forgets that a physicist cannot publish their work in a biology journal. Then one might argue that mega-journals publish all research, but given the constant consolidation processes in unregulated markets (which is alive and well also in the publishing market as was just reported), there quickly won’t be many of these around any more such they are, again, free to increase prices. No matter how I try to turn the arguments around, I only see incentives for price hikes that will render the new system just as unsustainable as the current one, only worse: failure to pay leads to a failure to make your discovery public and no #icanhazpdf can mitigate that. Again, as before, this kind of scenario can only be worse than what we have now.
tl:dr: The incentives for price hikes in a universal gold open access economy will be even stronger than they are today.













{kind=link}